Part 2: Provision
What Will You Do¶
In this part of the self-paced exercise, you will provision an Amazon EKS cluster with a GPU node group based on a declarative cluster specification and create an Amazon S3 bucket which will contain the inference server models.
Step 1: Cluster Spec¶
- Open Terminal (on macOS/Linux) or Command Prompt (Windows) and navigate to the folder where you forked the Git repository
- Navigate to the folder "
/getstarted/tritoneks/cluster"
The "eks-gpu-triton.yaml" file contains the declarative specification for our Amazon EKS Cluster.
Cluster Details¶
The following items may need to be updated/customized if you made changes to these or used alternate names.
- cluster name: eks-gpu-triton
- cloud provider: aws-cloud-credential
- project: defaultproject
- region: us-west-2
- ami: ami-0114d85734fee93fb
Step 2: Provision Cluster¶
- On your command line, navigate to the "cluster" sub folder
- Type the command
rctl apply -f eks-gpu-triton.yaml
If there are no errors, you will be presented with a "Task ID" that you can use to check progress/status. Note that this step requires creation of infrastructure in your AWS account and can take ~20-30 minutes to complete.
{
"taskset_id": "72dqj3m",
"operations": [
{
"operation": "ClusterCreation",
"resource_name": "eks-gpu-triton",
"status": "PROVISION_TASK_STATUS_PENDING"
},
{
"operation": "NodegroupCreation",
"resource_name": "t3-nodegroup",
"status": "PROVISION_TASK_STATUS_PENDING"
},
{
"operation": "NodegroupCreation",
"resource_name": "gpu-nodegroup",
"status": "PROVISION_TASK_STATUS_PENDING"
},
{
"operation": "BlueprintSync",
"resource_name": "eks-gpu-triton",
"status": "PROVISION_TASK_STATUS_PENDING"
}
],
"comments": "The status of the operations can be fetched using taskset_id",
"status": "PROVISION_TASKSET_STATUS_PENDING"
}
- Navigate to the project in your Org
- Click on Infrastructure -> Clusters. You should see something like the following

- Click on the cluster name to monitor progress
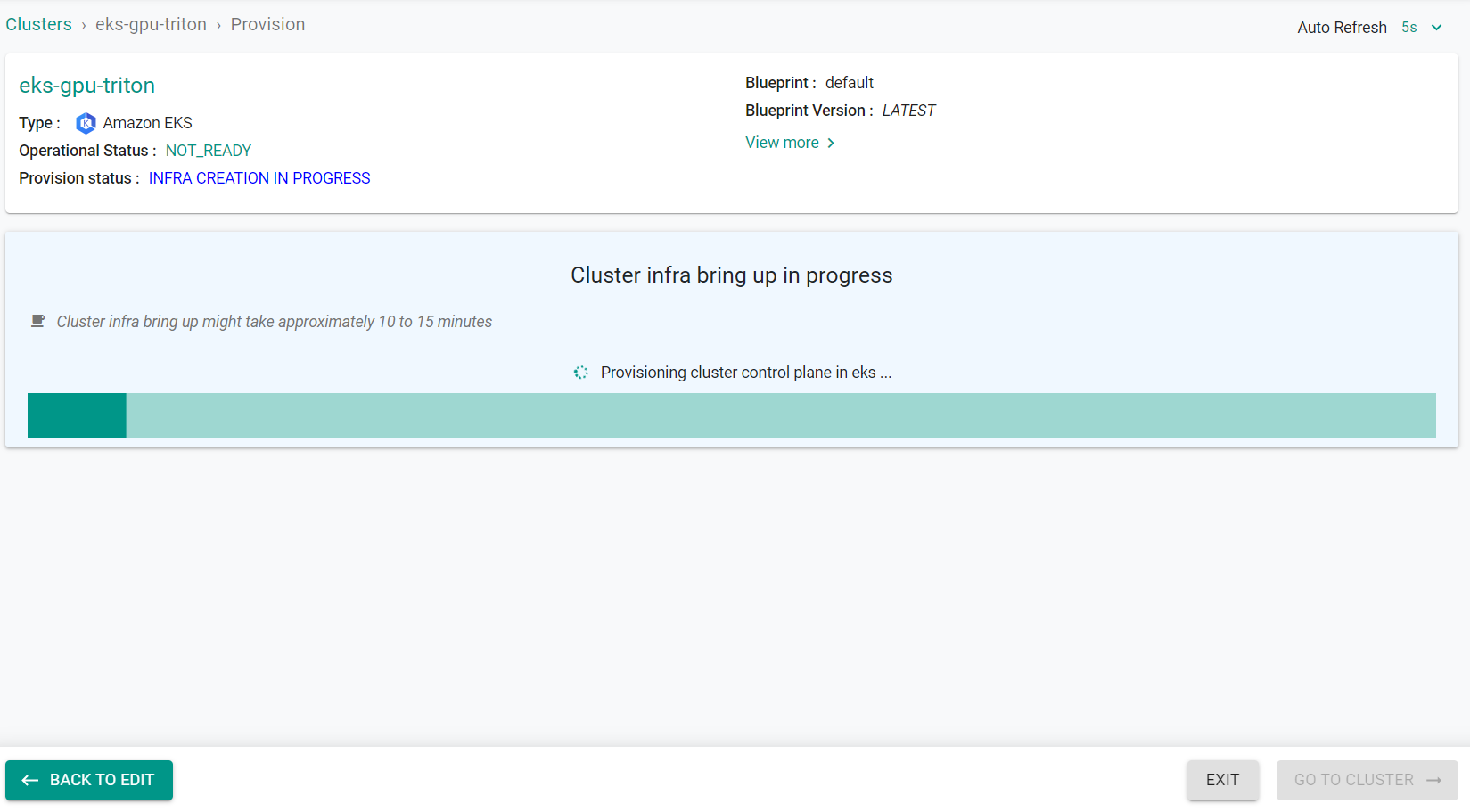
Step 3: Verify Cluster¶
Once provisioning is complete, you should see a healthy cluster in the web console
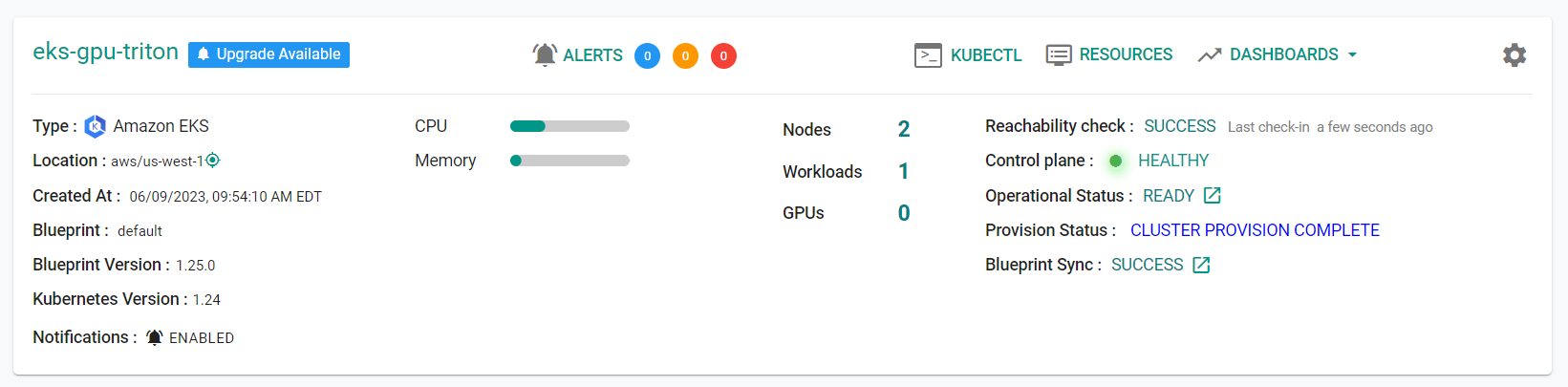
- Click on the kubectl link and type the following command
kubectl get nodes -o wide
You should see something like the following
NAME STATUS ROLES AGE VERSION INTERNAL-IP EXTERNAL-IP OS-IMAGE KERNEL-VERSION CONTAINER-RUNTIME
ip-192-168-31-17.us-west-2.compute.internal Ready <none> 16m v1.24.10 192.168.31.17 54.153.68.143 Ubuntu 20.04.6 LTS 5.15.0-1034-aws containerd://1.6.12
ip-192-168-86-86.us-west-2.compute.internal Ready <none> 17m v1.24.13-eks-0a21954 192.168.86.86 <none> Amazon Linux 2 5.10.179-166.674.amzn2.x86_64 containerd://1.6.19
Step 3: Remove EKS GPU Daemonset¶
You will now remove the EKS installed Nvidia daemonset. This daemonset will install the GPU drivers. However, we will be using the Nvidia Operator which will install the needed drivers.
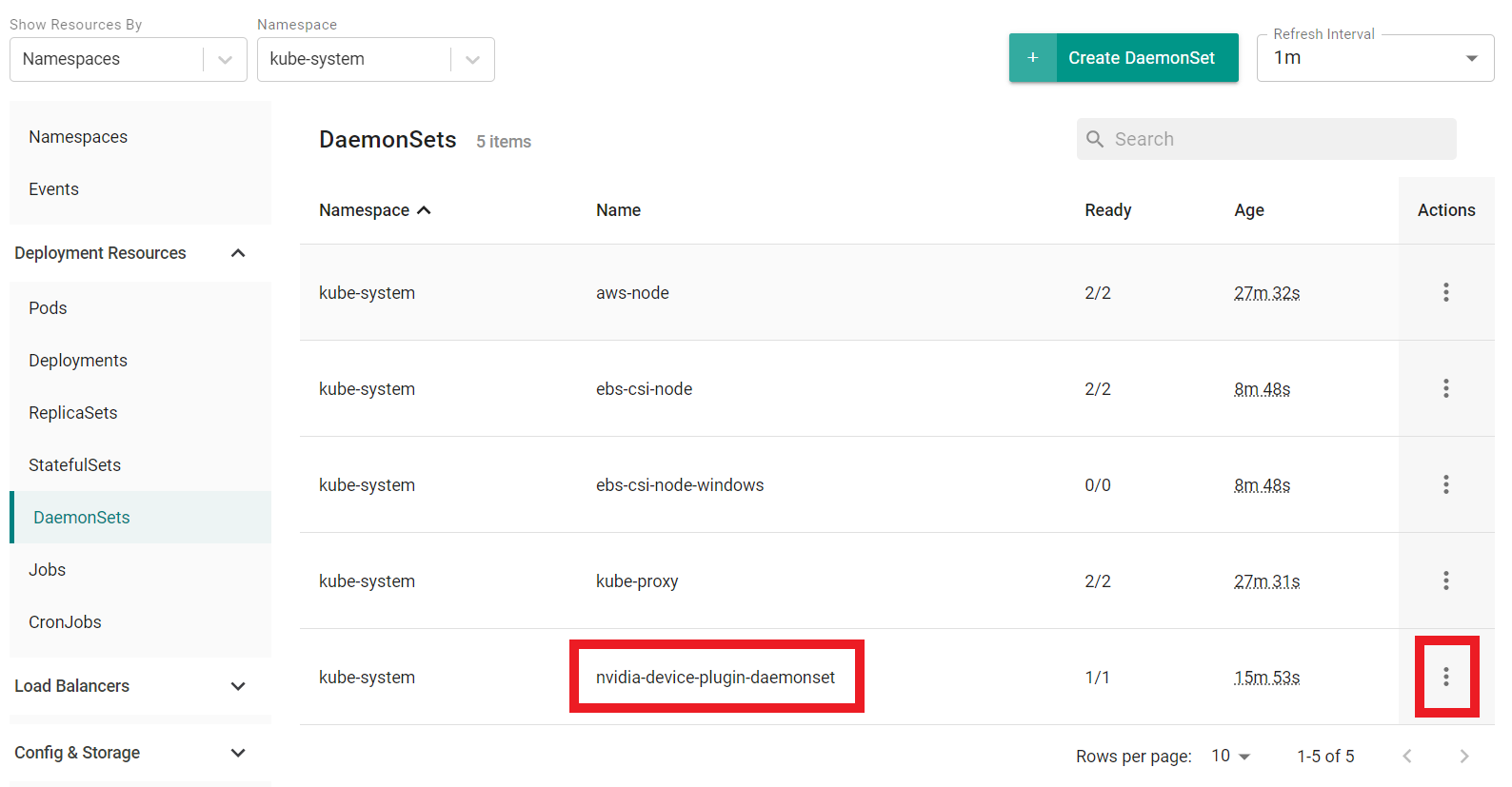
- Navigate to Infrastructure -> Clusters
- Click on Resources on the cluster card
- Click on DaemonSets on the left hand side of the page
- Find the daemonset with the name nvidia-device-plugin-daemonset
- Click on the actions button next to the previously located daemonset
- Click Delete
- Click Yes to confirm the deletion
Step 4: Clone Triton Git Repository¶
You will now clone the Triton Git Repository to your machine. This repository contains the models that will be used in this guide.
- Clone the Git repository to your laptop using the command below.
git clone https://github.com/triton-inference-server/server.git
- Once complete, you should see a folder called server which contains the models and other resources.
Step 5: Update Models¶
We must update the models with the latest data. To do this, we will run a shell script.
- Navigate to server/docs/examples in the previously cloned Triton repository
- Run the fetch_models.sh script to update the models
Step 6: Create S3 Bucket¶
The Triton Server needs a repository of models that it will make available for inferencing. For this example you will place the model repository in an AWS S3 Storage bucket. You will use the AWS CLI to create an S3 bucket. We will then copy example models into the bucket. These models will be used by the inference server in a later step.
- Run the following command to create an S3 bucket
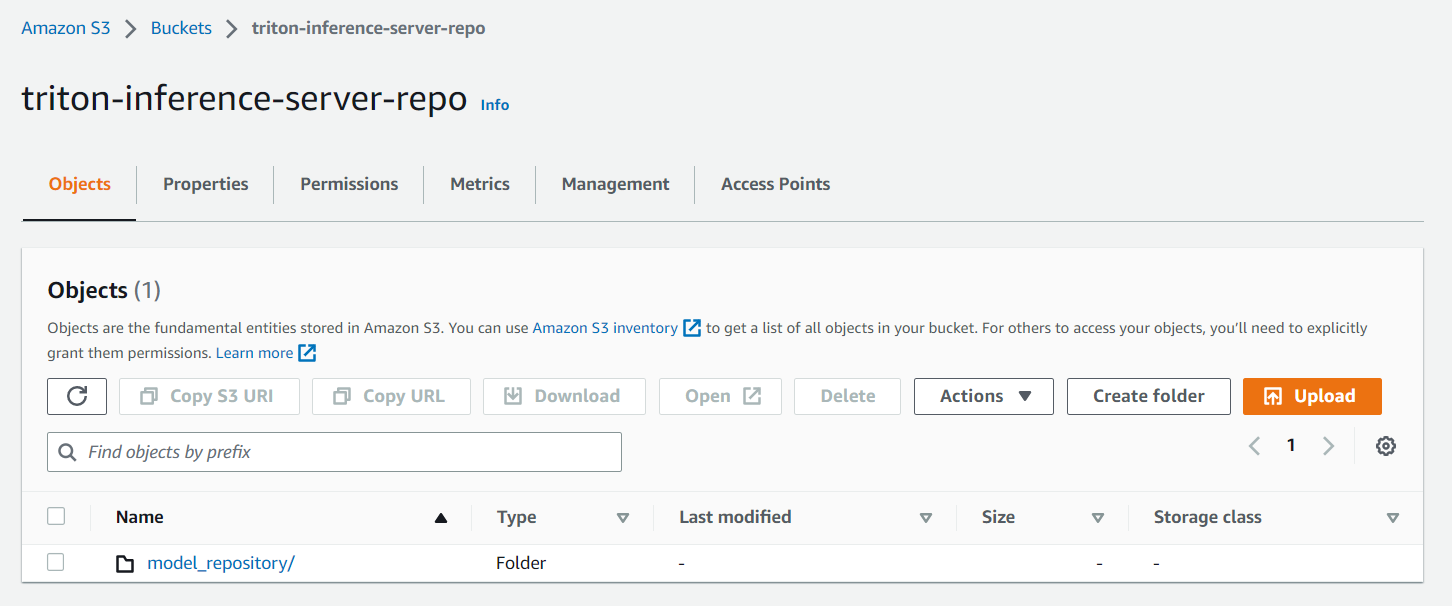
aws s3 mb s3://triton-inference-server-repo
- Run the following command to copy the models from the clones Triton repository to the S3 bucket
aws s3 cp --recursive docs/examples/model_repository s3://triton-inference-server-repo/model_repository
You should now see the models in your S3 bucket
Recap¶
Congratulations! At this point, you have successfully configured and provisioned an Amazon EKS cluster with a GPU node group in your AWS account using the RCTL CLI and created an Amazon S3 bucket with inference models. You are now ready to move on to the next step where you will create a deploy a custom cluster blueprint that contains the Nvidia GPU Operator as an addon.