Install
In this exercise,
- You will create a "nvidia-gpu-operator" addon and use it in a custom cluster blueprint
- You will then apply this cluster blueprint to a managed cluster to automate the management of NVIDIA software components to provision GPU including NVIDIA drivers, device plugin for GPUs, NVIDIA Container Toolkit, automatic node labelling, monitoring, ...
Important
This tutorial describes the steps to create and use a custom cluster blueprint using the Web Console. The entire workflow can also be fully automated and embedded into an automation pipeline using the RCTL CLI or the REST APIs.
This recipe uses the Rafay App Catalog to simplify the process of creating a custom add-on. The Catalog provides pre-configured with access to Helm repositories for supported applications
Assumptions¶
- You have already provisioned or imported one or more Kubernetes clusters using the controller.
- Ensure that your Kubernetes nodes are NOT pre-configured with NVIDIA components (driver, device plugin, ...)
- If Kubernetes worker nodes are running in virtualization environment (VMware, KVM, ...), NVIDIA vGPU Host Driver version 12.0 (or later) should be pre-installed on all hypervisors hosting the virtual machines
- Ensure that no GPU components has been deployed in the Kubernetes like Device Plugin for GPUs, Node Feature Discovery etc.
Important
For RHEL OS, Nvidia's GPU Operator will install and configure the required GPU drivers automatically on the underlying nodes in the Kubernetes cluster as long as the underlying RHEL based node OS is enabled with proper subscription and entitlement with RedHat. If you have disabled this due to licensing cost issues etc, you will be required to install and manage the lifecycle of the GPU drivers manually.
Step 1: Customize Values¶
The gpu-operator Helm chart comes with a very detailed values.yaml file with support for default configuration. You can also customize the defaults with your own override "values.yaml" if you would like to use a different default runtime than docker, a custom driver image, or using vGPU, ...
Copy the details below into a file named "gpu-operator-custom-values.yaml" and make the changes applicable to your deployment.
Note
Reference on detail steps of gpu-operator installation can be found here
## Custom values for gpu-operator.
## Set to false if Node Feature Discovery is already deployed in the cluster
nfd:
enabled: true
operator:
## Update the default runtime if using cri-o or containerd
defaultRuntime: docker
mig:
## Update the MIG strategy here if your hardware supports MIG
strategy: none
## Update driver repository, image, version, ... if you want to use custom driver container images or NVIDIA vGPUs
## The GPU Operator with NVIDIA vGPUs requires additional steps to build a private driver image here:
## https://docs.nvidia.com/datacenter/cloud-native/gpu-operator/install-gpu-operator-vgpu.html#considerations-to-install-gpu-operator-with-nvidia-vgpu-driver
driver:
## Enable deploying NVIDIA Driver. Use "enabled: false" if NVIDIA driver software has been installed in the node.
## For EKS cluster with node group using GPU instance, the Amazon EKS AMI has the NVIDIA driver installed by default. In this case, use "enabled: false" to not deploy the driver
enabled: true
repository: nvcr.io/nvidia
image: driver
version: "470.57.02"
imagePullPolicy: IfNotPresent
imagePullSecrets: []
# vGPU licensing configuration
licensingConfig:
configMapName: ""
nlsEnabled: false
# vGPU topology daemon configuration
virtualTopology:
config: ""
## Enable/Disable container toolkit
toolkit:
enabled: true
## Enable/Disable dcgm
dcgm:
enabled: true
## Enable/Disable MIG Manager.Enable this only if your hardware supports MIG
migManager:
enabled: false
## Enable/Disable nodeStatusExporter
nodeStatusExporter:
enabled: false
Step 2: Create Addon¶
- Login into the Web Console and navigate to your Project as an Org Admin or Infrastructure Admin
- Under Infrastructure, select "Namespaces" and create a new namespace called "gpu-operator-resources"
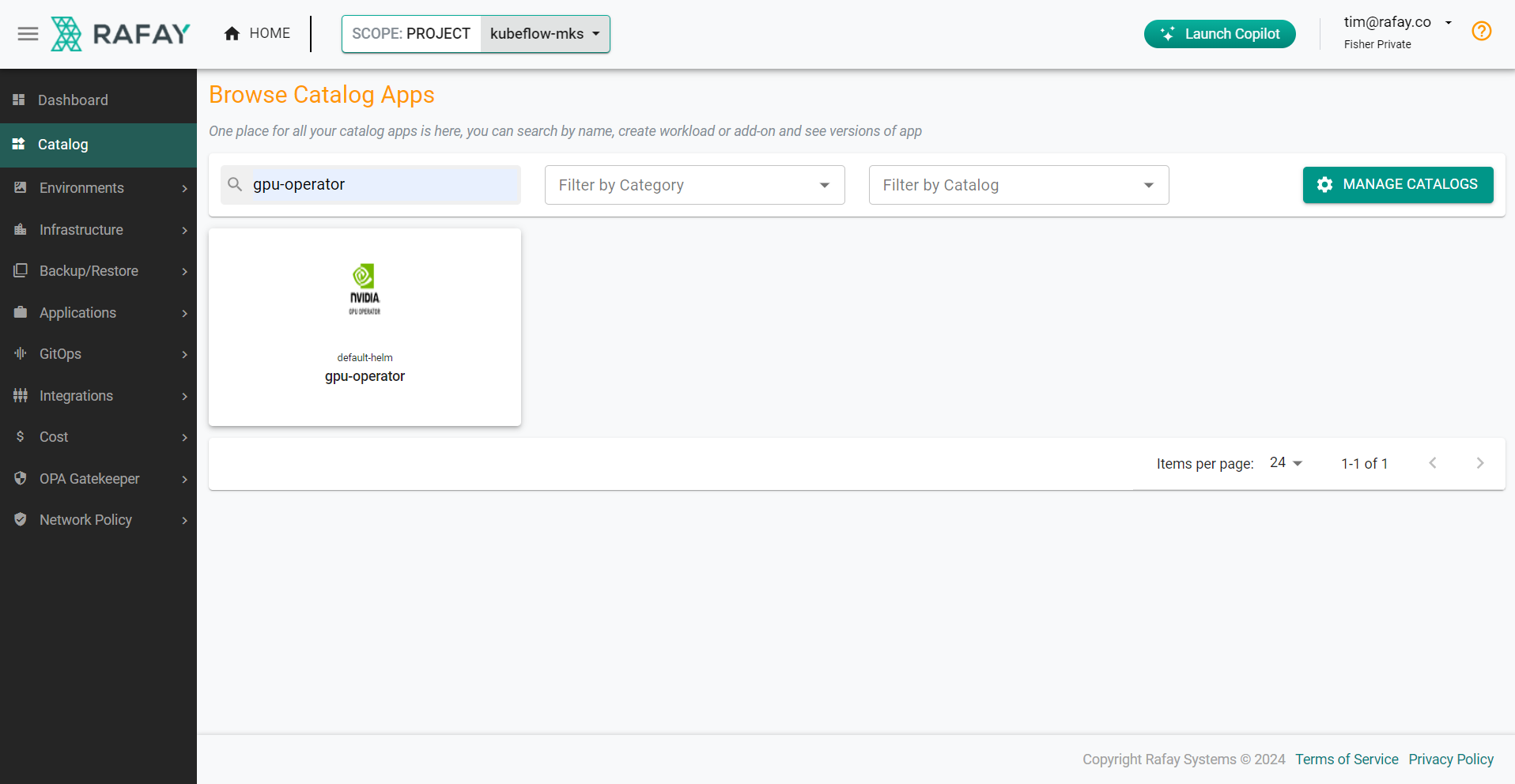
- Select "Addons" and "New Add-On -> Create New Add-On from Catalog"
- Search for "gpu-operator" and select it
- Click "Create Add-On"
- Enter a name for the add-on and select the namespace as "gpu-operator-resources"
- Click "Create"
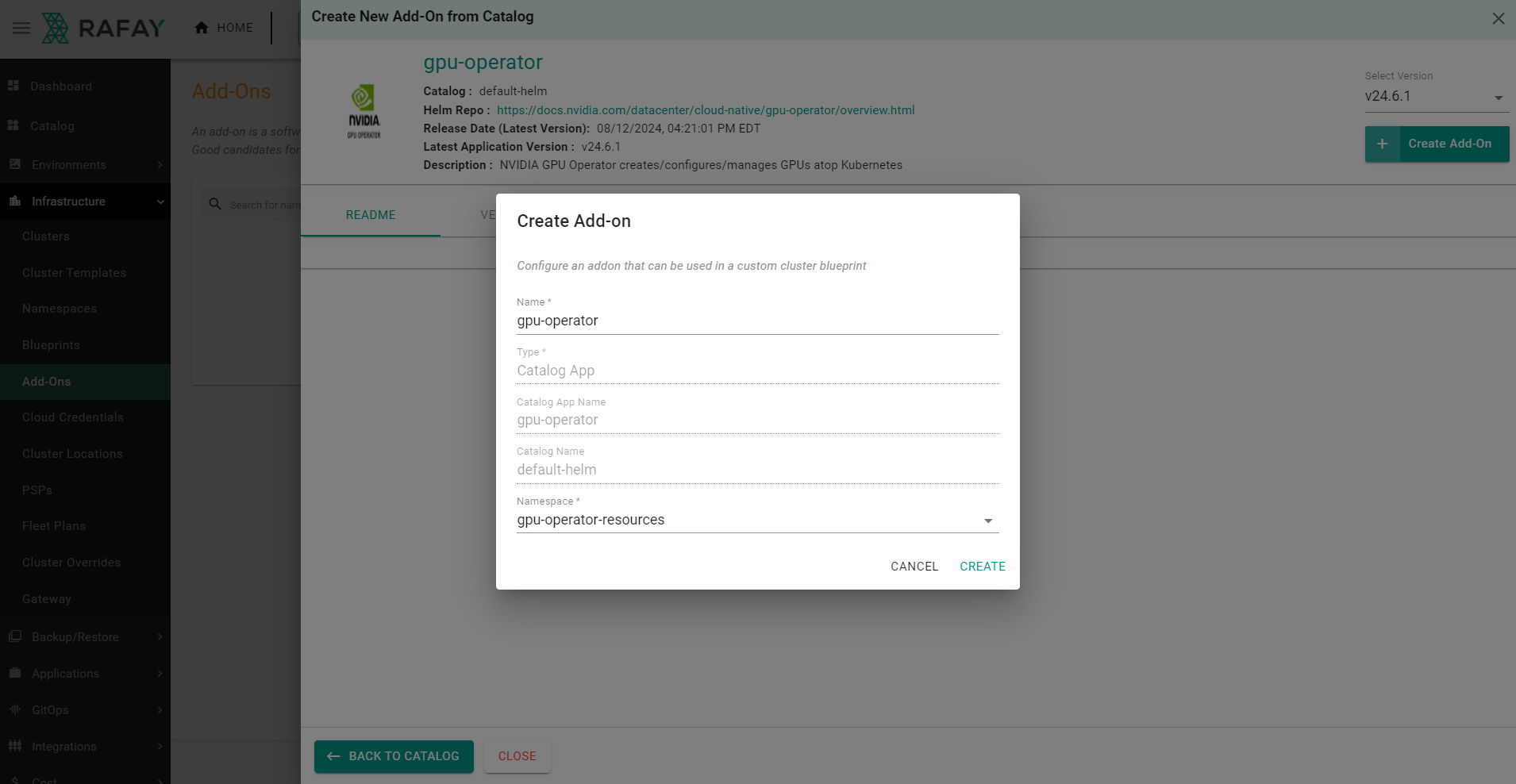
- Set the version name and upload the "gpu-operator-custom-values.yaml" file
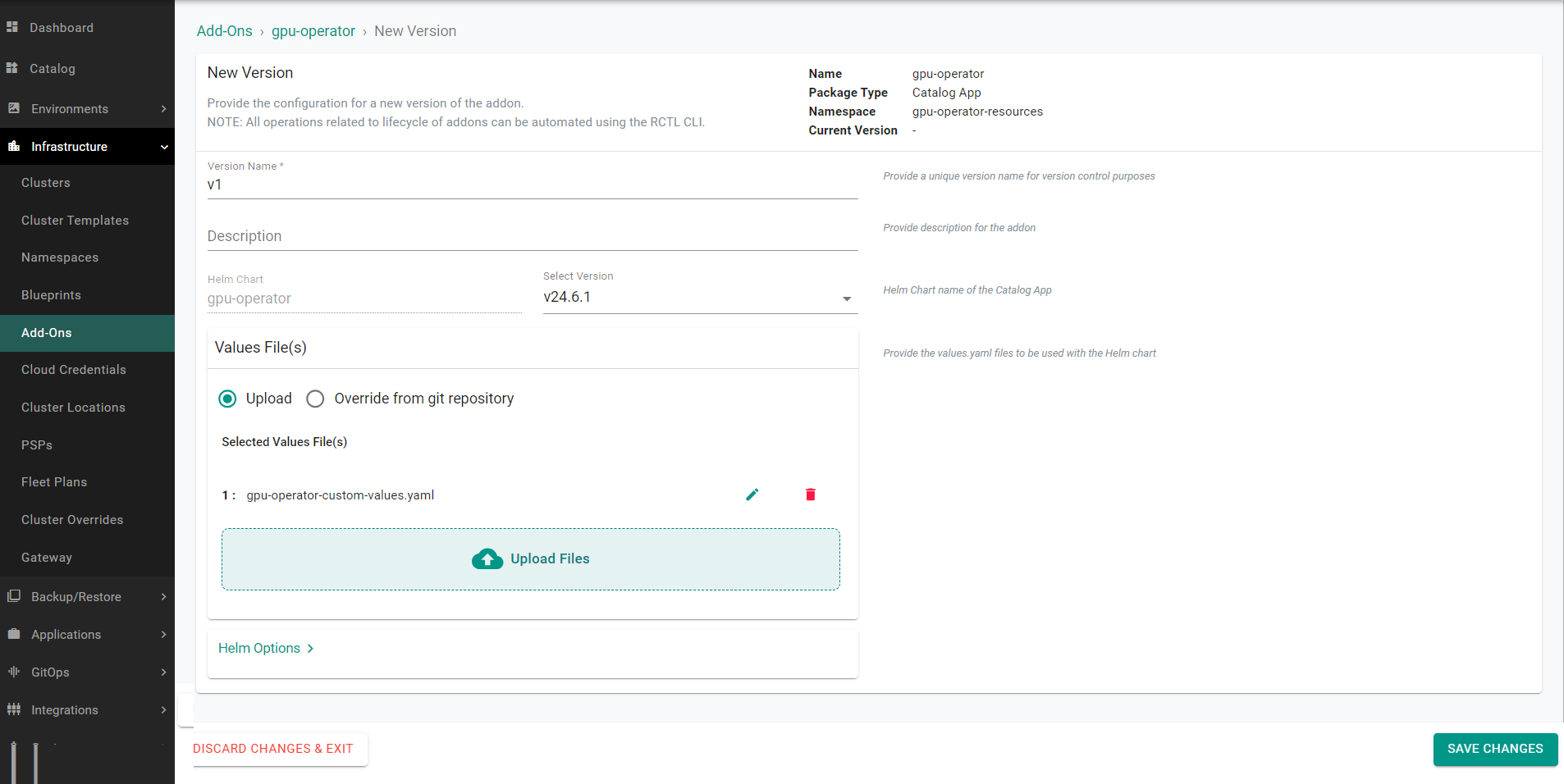
- Save the changes
- Ensure the "gpu-operator" addon version has been successfully created.
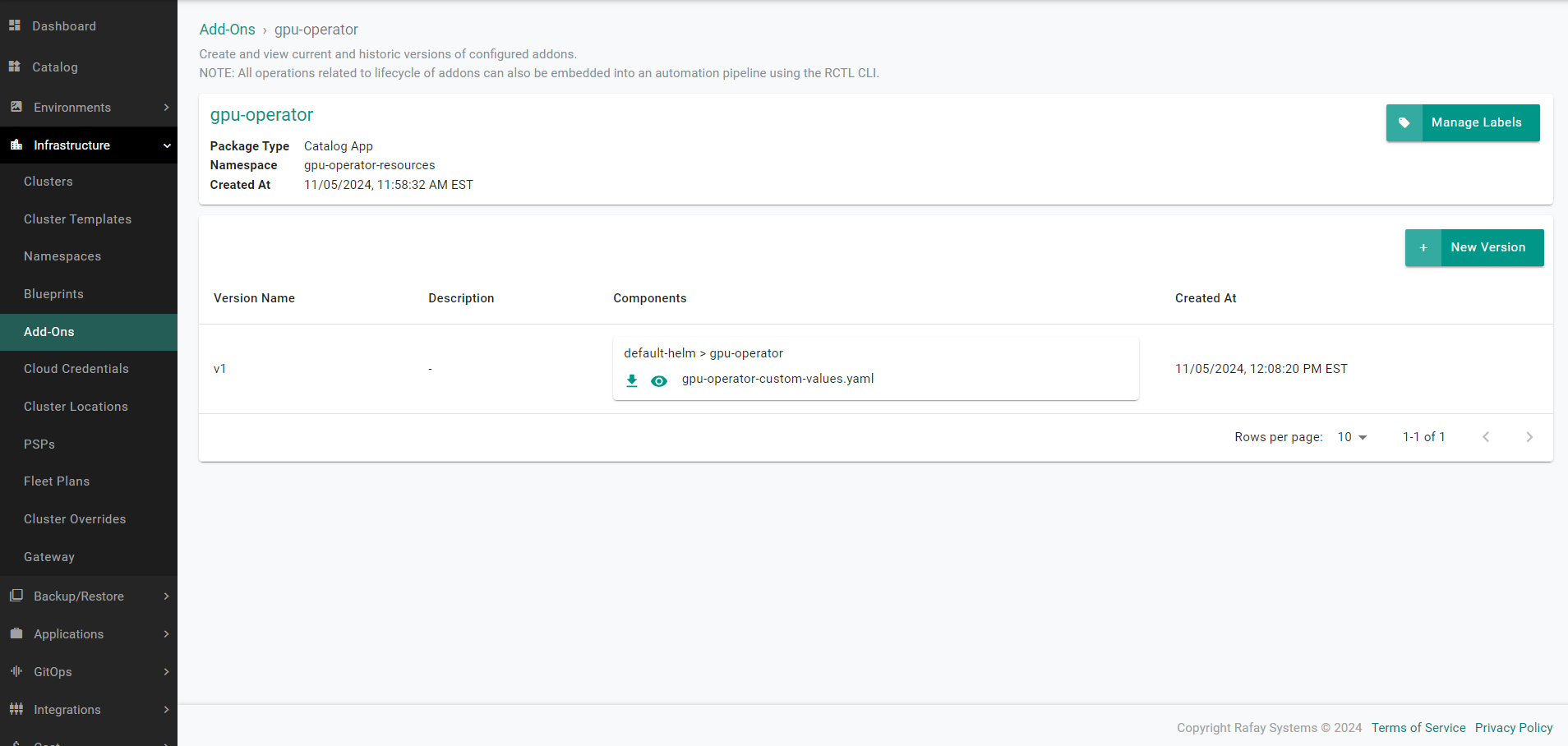
Step 3: Create Blueprint¶
Now, we are ready to assemble a custom cluster blueprint using the newly created gpu-operator addon. You can add other addons to the same custom blueprint as well.
- Under Infrastructure, select "Blueprints"
- Create a new blueprint and give it a name such as "standard-blueprint"
- Create a new blueprint version
- Enter version name and select the gpu-operator, its version and other addons as required
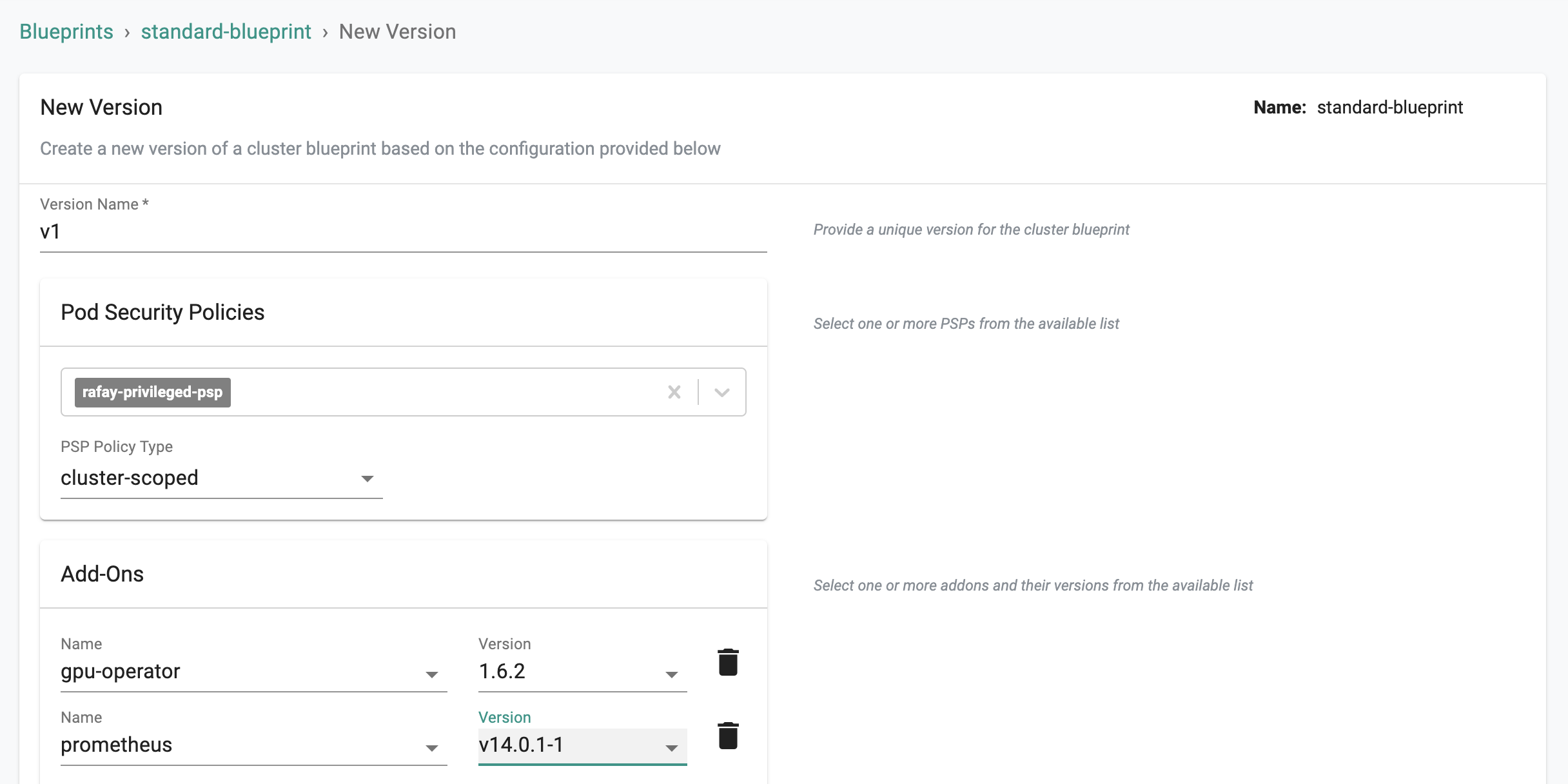
- Save the changes
- Ensure the new version of the blueprint is created.
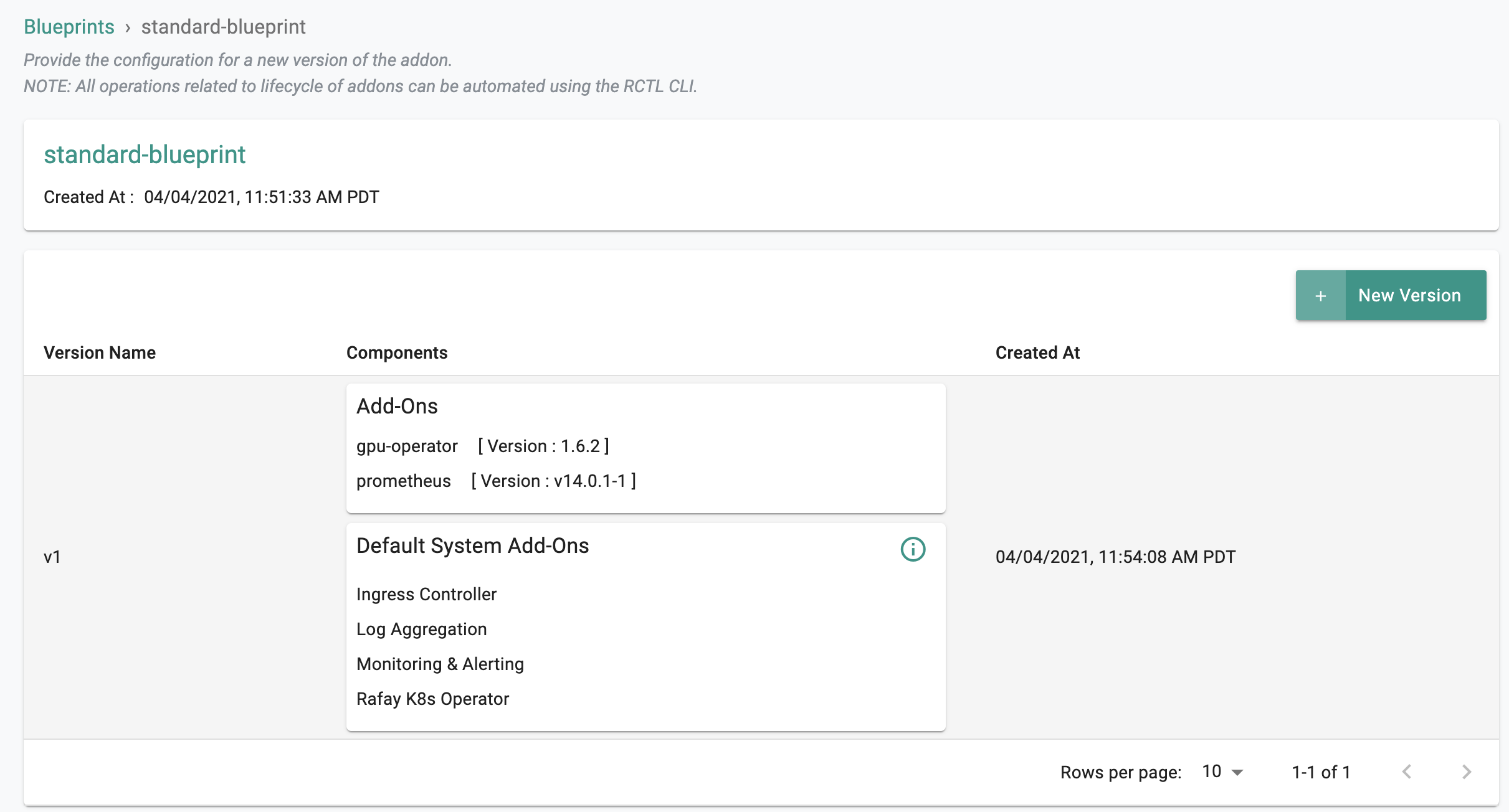
Step 4: Apply Blueprint¶
Now, we are ready to apply this custom blueprint to a cluster.
- Click on Options for the target Cluster in the Web Console
- Select "Update Blueprint" and select the "standard-blueprint" blueprint from the list and select the version to apply to the cluster.
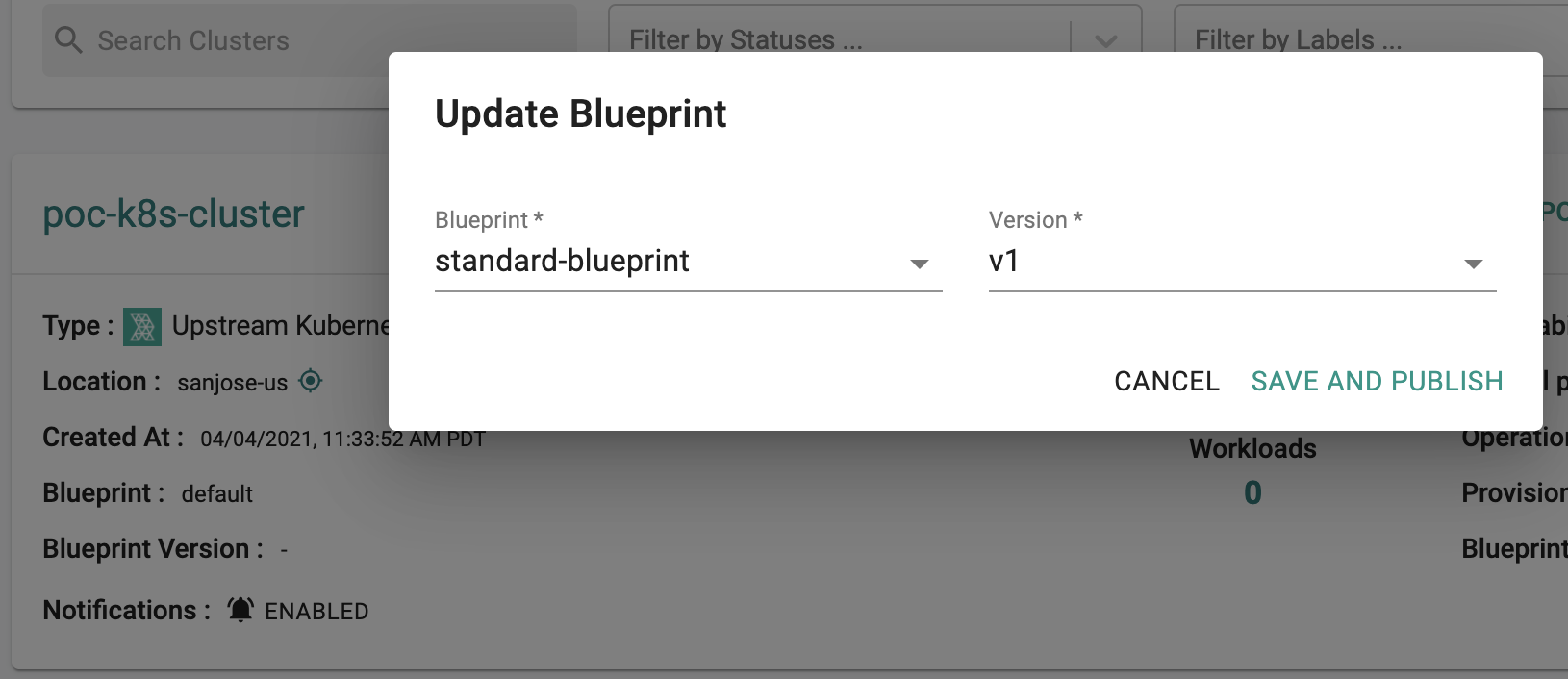
- Click on "Save and Publish".
This will start the deployment of the addons configured in the "standard-blueprint" blueprint to the targeted cluster. The blueprint sync process can take a few minutes. Once complete, the cluster will display the current cluster blueprint details and whether the sync was successful or not.
Step 5: Verify Deployment¶
Users can optionally verify whether the correct resources for the GPU Operator have been created on the cluster. Click on the Kubectl button on the cluster to open a virtual terminal
Namespace¶
- Verify if the "gpu-operator-resources" namespace has been created
kubectl get ns gpu-operator-resources
NAME STATUS AGE
gpu-operator-resources Active 2m
GPU Operator Pods¶
- Verify the gpu-operator pods are deployed in the "gpu-operator-resources" namespace. You should see something like the example below.
kubectl get pod -n gpu-operator-resources
NAME READY STATUS RESTARTS AGE
gpu-operator-7d89cddbbd-9tvn9 1/1 Running 0 81s
gpu-operator-node-feature-discovery-master-66688f44dd-r44ql 1/1 Running 0 81s
gpu-operator-node-feature-discovery-worker-8bd62 1/1 Running 0 81s
gpu-operator-node-feature-discovery-worker-mnrnw 1/1 Running 0 81s
GPU Operator-Resources¶
- Verify the nvidia-driver, nvidia-device-plugin, nvidia-container-toolkit, nvidia-dcgm-exporter, ... pods are deployed successfully in the nodes which have GPU
kubectl get pod -n gpu-operator-resources -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
nvidia-container-toolkit-daemonset-jcshf 1/1 Running 0 4m37s 10.244.1.31 poc-k8s-cluster-gpu-node1 <none> <none>
nvidia-dcgm-exporter-b9wg6 1/1 Running 0 2m36s 10.244.1.34 poc-k8s-cluster-gpu-node1 <none> <none>
nvidia-device-plugin-daemonset-qxx8g 1/1 Running 0 3m4s 10.244.1.32 poc-k8s-cluster-gpu-node1 <none> <none>
nvidia-device-plugin-validation 0/1 Completed 0 2m48s 10.244.1.33 poc-k8s-cluster-gpu-node1 <none> <none>
nvidia-driver-daemonset-p89d5 1/1 Running 0 5m17s 10.244.1.30 poc-k8s-cluster-gpu-node1 <none> <none>
Driver Logs¶
- Verify the nvidia-driver logs and ensure the nvidia-driver installed successfully to the GPU nodes.
kubectl logs -n gpu-operator-resources nvidia-driver-daemonset-p89d5
========== NVIDIA Software Installer ==========
Starting installation of NVIDIA driver version 460.32.03 for Linux kernel version 5.4.0-1038-aws
Stopping NVIDIA persistence daemon...
Unloading NVIDIA driver kernel modules...
Unmounting NVIDIA driver rootfs...
Checking NVIDIA driver packages...
Updating the package cache...
...
Welcome to the NVIDIA Software Installer for Unix/Linux
Detected 4 CPUs online; setting concurrency level to 4.
Installing NVIDIA driver version 460.32.03.
A precompiled kernel interface for kernel '5.4.0-1038-aws' has been found here: ./kernel/precompiled/nvidia-modules-5.4.0.
Kernel module linked successfully.
...
Installing 'NVIDIA Accelerated Graphics Driver for Linux-x86_64' (460.32.03):
Installing: [##############################] 100%
Driver file installation is complete.
Running post-install sanity check:
Checking: [##############################] 100%
Post-install sanity check passed.
Running runtime sanity check:
Checking: [##############################] 100%
Runtime sanity check passed.
Installation of the kernel module for the NVIDIA Accelerated Graphics Driver for Linux-x86_64 (version 460.32.03) is now complete.
Loading ipmi and i2c_core kernel modules...
Loading NVIDIA driver kernel modules...
Starting NVIDIA persistence daemon...
Mounting NVIDIA driver rootfs...
Done, now waiting for signal
- Verify the nvidia-device-plugin logs and ensure the nvidia-device-plugin installed successfully to the GPU nodes.
kubectl logs -n gpu-operator-resources nvidia-device-plugin-daemonset-qxx8g
nvidia 34037760 17 nvidia_modeset,nvidia_uvm, Live 0xffffffffc0c4c000 (POE)
2021/04/04 19:05:03 Loading NVML
2021/04/04 19:05:03 Starting FS watcher.
2021/04/04 19:05:03 Starting OS watcher.
2021/04/04 19:05:03 Retreiving plugins.
2021/04/04 19:05:03 No MIG devices found. Falling back to mig.strategy=&{}
2021/04/04 19:05:03 Starting GRPC server for 'nvidia.com/gpu'
2021/04/04 19:05:03 Starting to serve 'nvidia.com/gpu' on /var/lib/kubelet/device-plugins/nvidia-gpu.sock
2021/04/04 19:05:03 Registered device plugin for 'nvidia.com/gpu' with Kubelet
GPU Labels¶
- Verify that the GPU nodes have been automatically injected with required GPU labels
- You can view this either via Kubectl or via the node dashboards on the web console
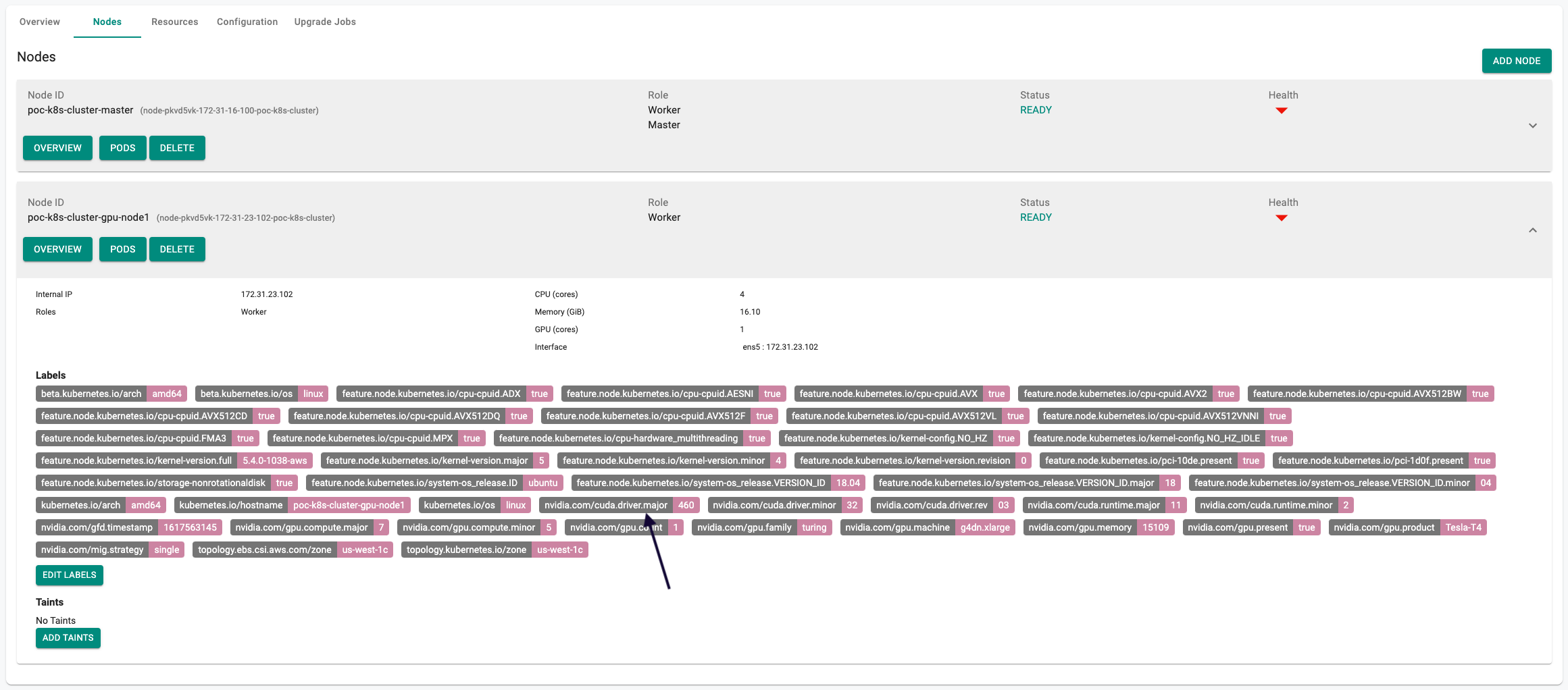
kubectl describe nodes poc-k8s-cluster-gpu-node1
Name: poc-k8s-cluster-gpu-node1
Roles: <none>
Labels: beta.kubernetes.io/arch=amd64
beta.kubernetes.io/os=linux
feature.node.kubernetes.io/cpu-cpuid.ADX=true
...
kubernetes.io/arch=amd64
kubernetes.io/hostname=poc-k8s-cluster-gpu-node1
kubernetes.io/os=linux
nvidia.com/cuda.driver.major=460
nvidia.com/cuda.driver.minor=32
nvidia.com/cuda.driver.rev=03
nvidia.com/cuda.runtime.major=11
nvidia.com/cuda.runtime.minor=2
nvidia.com/gfd.timestamp=1617563145
nvidia.com/gpu.compute.major=7
nvidia.com/gpu.compute.minor=5
nvidia.com/gpu.count=1
nvidia.com/gpu.family=turing
nvidia.com/gpu.machine=g4dn.xlarge
nvidia.com/gpu.memory=15109
nvidia.com/gpu.present=true
nvidia.com/gpu.product=Tesla-T4
nvidia.com/mig.strategy=single
- Correspondingly, the non-GPU nodes should NOT have the GPU labels
kubectl describe nodes poc-k8s-cluster-master
Name: poc-k8s-cluster-master
Labels: beta.kubernetes.io/arch=amd64
beta.kubernetes.io/os=linux
feature.node.kubernetes.io/cpu-cpuid.ADX=true
feature.node.kubernetes.io/cpu-cpuid.AESNI=true
...
feature.node.kubernetes.io/system-os_release.VERSION_ID.minor=04
kubernetes.io/arch=amd64
kubernetes.io/hostname=poc-k8s-cluster-master
kubernetes.io/os=linux
node-role.kubernetes.io/master=
Recap¶
Congratulations! You have successfully created a custom cluster blueprint with the "gpu-operator" addon and applied to a cluster. You can now use this blueprint on as many clusters as you require.
With this gpu-operator addon, it will automate the management of NVIDIA software components to provision GPU including NVIDIA drivers, device plugin for GPUs, NVIDIA Container Toolkit, automatic node labelling, monitoring, ...
Any new GPU nodes added to the cluster will be detected and had NVIDIA GPU software components deployed automatically