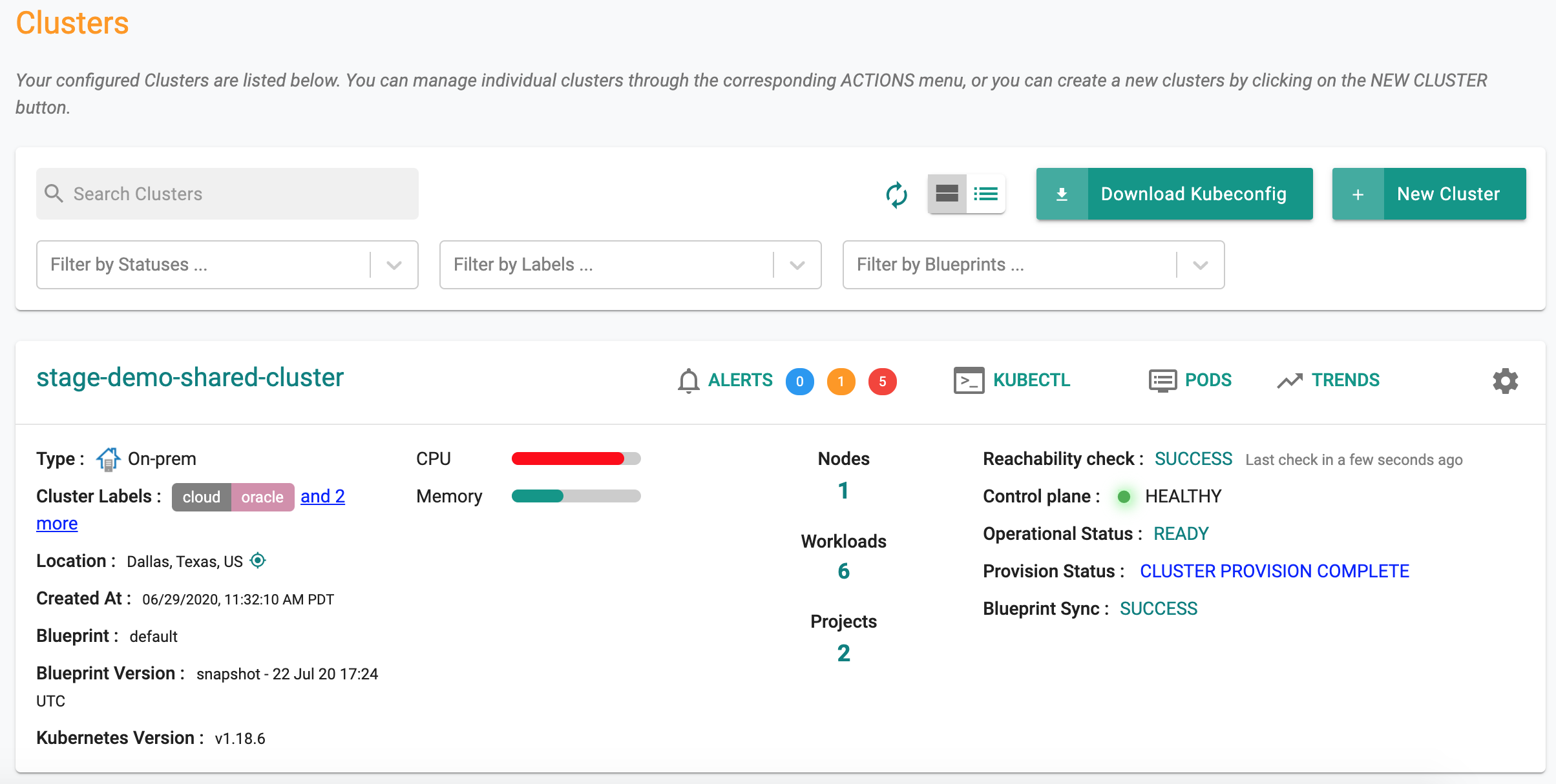
Alerts
The Controller continuously monitors both clusters and workloads deployed on the managed clusters. When a critical issue with the cluster or the workload is detected, the Controller generates an "Alert".
Alerts are generated when observed events "persist" and are unable to resolve automatically after a number of retries. The entire history of "Alerts" is persisted on the Controller and a reverse chronological history is available to Org Admins on the Console.
Alert Lifecycle¶
All Alerts start life as "Open Alerts". When the underlying issue is resolved (automatically or manually) and the issue does not manifest anymore, the alert is automatically "Closed".
Filters are provided to help sort and manage the alerts appropriately:
- Project
- Alerts Status (Open/Closed)
- Type
- Cluster
- Severity
- Time Range
For every alert, the following data is presented to the user:
- Date: When the issue was first observed and therefore the alert was generated automatically
- Duration: How long the issue has persisted
- Type: See details below
- Cluster: The cluster in which the issue was observed
- Severity: How severe is this alert (Critical/Warning/Info)
- Summary: Brief description of the issue
- Description: Detailed description of the issue behind the alert

Alert Severity¶
All alerts have an associated Severity. A CRITICAL alert means the administrator needs to pay attention immediately to help address the underlying issue. A WARNING severity means there is an underlying issue that is trending poorly and will need attention quickly. An Info severity is mostly for Informational purposes only.
SLA¶
For application and ops teams, SLA can be a critical measure of their effectiveness. The "duration" of the alert provides an excellent indication of SLA. Issues should ideally be triaged and resolved ASAP in minutes.
Manage Notifications¶
You can configure which system alerts you want to receive and specify the email recipients for notifications.
Notifications¶
Under Notifications, you can enable or disable alerts for specific monitored objects. When enabled, notifications are triggered whenever relevant events occur in the environment.
| Notification Type | Description | Default State |
|---|---|---|
| Cluster | Receive notifications related to overall cluster health and connectivity. | Enabled |
| Pod | Alerts for pod-related events such as failures, restarts, or unhealthy status. | Enabled |
| Node | Monitors node availability and performance metrics like CPU, memory, and status. | Enabled |
| PVC | Tracks Persistent Volume Claims for binding or capacity issues. | Enabled |
| Agent Health | Alerts when an agent loses connectivity or becomes unhealthy. | Enabled |
Users can toggle the switch next to each notification type to enable or disable alerts as needed.
Recipient Emails¶
Under Recipient Emails, you can manage who receives these notifications.
- Add or delete recipient email addresses using the Add and Delete (🗑️) icons.
- Only valid email formats are accepted.
- All listed recipients will receive email notifications for the enabled categories.
Actions:
- Click Add to include a new email address.
- Click the trash icon to remove an existing email.
- Select Save to confirm your configuration.
- Choose Cancel to discard changes.
Alerts Quick View¶
Cluster administrators are provided with a quick view of all open alerts associated with a cluster. In the Console, navigate to the cluster card to get a bird's eye view of open alerts.