Overview
It is common for many organizations to want to leverage GPU containers for testing, development and running AI workloads. Kubernetes provides access to special hardware resources such as NVIDIA GPUs through the device plugin framework. However, configuring and managing nodes with these hardware resources requires configuration of multiple software components such as drivers, container runtimes or other libraries. This is a very difficult, cumbersome and error prone process.
The GPU Operator¶
The recently introduced Operator Framework within Kubernetes allows the creation of an automated framework for the deployment of applications within Kubernetes using standard Kubernetes APIs.
The NVIDIA GPU Operator is based on the operator framework and automates the management of all NVIDIA software components needed to provision GPUs within Kubernetes. The GPU Operator is specifically designed to make large-scale hybrid-cloud and edge operations operationally efficient. The GPU operator is fully open-source and is available via Nvidia's GitHub Repository.
The GPU Operator simplifies both the "initial deployment" and "ongoing lifecycle management" of the components by containerizing all the components and using standard Kubernetes APIs for automating and managing these components including versioning and upgrades. These components include the NVIDIA drivers (to enable CUDA), Kubernetes device plugin for GPUs, the NVIDIA Container Toolkit, automatic node labelling using GFD, DCGM based monitoring and much more.
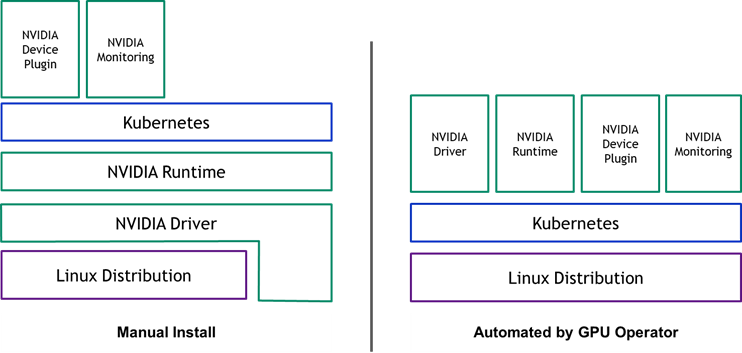
The operator is built as a new Custom Resource Definition (CRD) API with a corresponding controller. The operator runs in its own namespace (called “gpu-operator”) with the underlying NVIDIA components orchestrated in a separate namespace (“gpu-operator-resources”). The controller watches the namespace for changes and uses a reconciliation loop to implement a simple state machine for starting each of the NVIDIA components.
Additionally, the GPU Operator can now be installed in any namespace. To enable this, the GPU Operator option must be enabled, the resource type specified as either Service or Pod, and the required key-value labels added, which are mandatory for proper configuration. If the GPU Operator option is not enabled, the GPU Operator must be installed in the gpu-operator-resources namespace, maintaining the original behavior for dashboard functionality. This update provides flexibility in choosing the namespace for GPU Operator installation while ensuring compatibility with the original setup.
GPU Simulator¶
Users that do not have access to expensive GPUs or do not wish to spend money on GPUs for learning and testing purposes can use the GPU Operator Simulator software.
This was originally created by the Run.AI team (acquired by Nvidia in 2024). This recipe describes how to configure, install and use the GPU Simulator Operator to simulate the use of the GPU Operator software within a cluster.