Install
Users that do not have access to expensive GPUs or do not wish to spend money on GPUs for learning and testing can use the GPU Operator Simulator software. This was originally created by the Run.AI team (acquired by Nvidia). This recipe describes how to configure, install and use the GPU Simulator Operator to reduce costs and simulate the presence of GPUs within a cluster.
Note
In our testing, we have noticed a number of issues with the GPU Simulator Software. Please open a GitHub issue directly on the project's repo to report issues or request enhancements.
Assumptions¶
- You have provisioned or imported one or more Kubernetes clusters into a Project in your Rafay Org.
- Ensure that you have not already deployed the Nvidia GPU Operator on the cluster.
Note
In this recipe, you will notice that we are configuring and deploying the GPU Simulator software as a workload and not a Cluster Blueprint. Users can also deploy the simulator software to 100s of clusters in their Org by using a blueprint if required.
Deploy GPU Simulator¶
To deploy the GPU Simulator on the managed Kubernetes cluster, perform the following steps:
Step 1: Create GPU Simulator Helm Repository¶
Create a Helm repository that stores GPU Simulator Helm chart.
- Log in to the controller web console and navigate to your Project as an Org Admin or Infrastructure Admin.
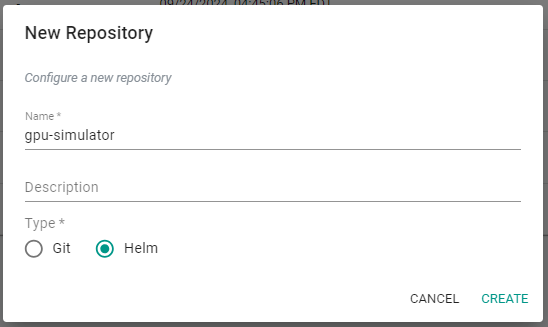
- Under Integrations, select Repositories and create a new Helm repository with the name
gpu-simulator.
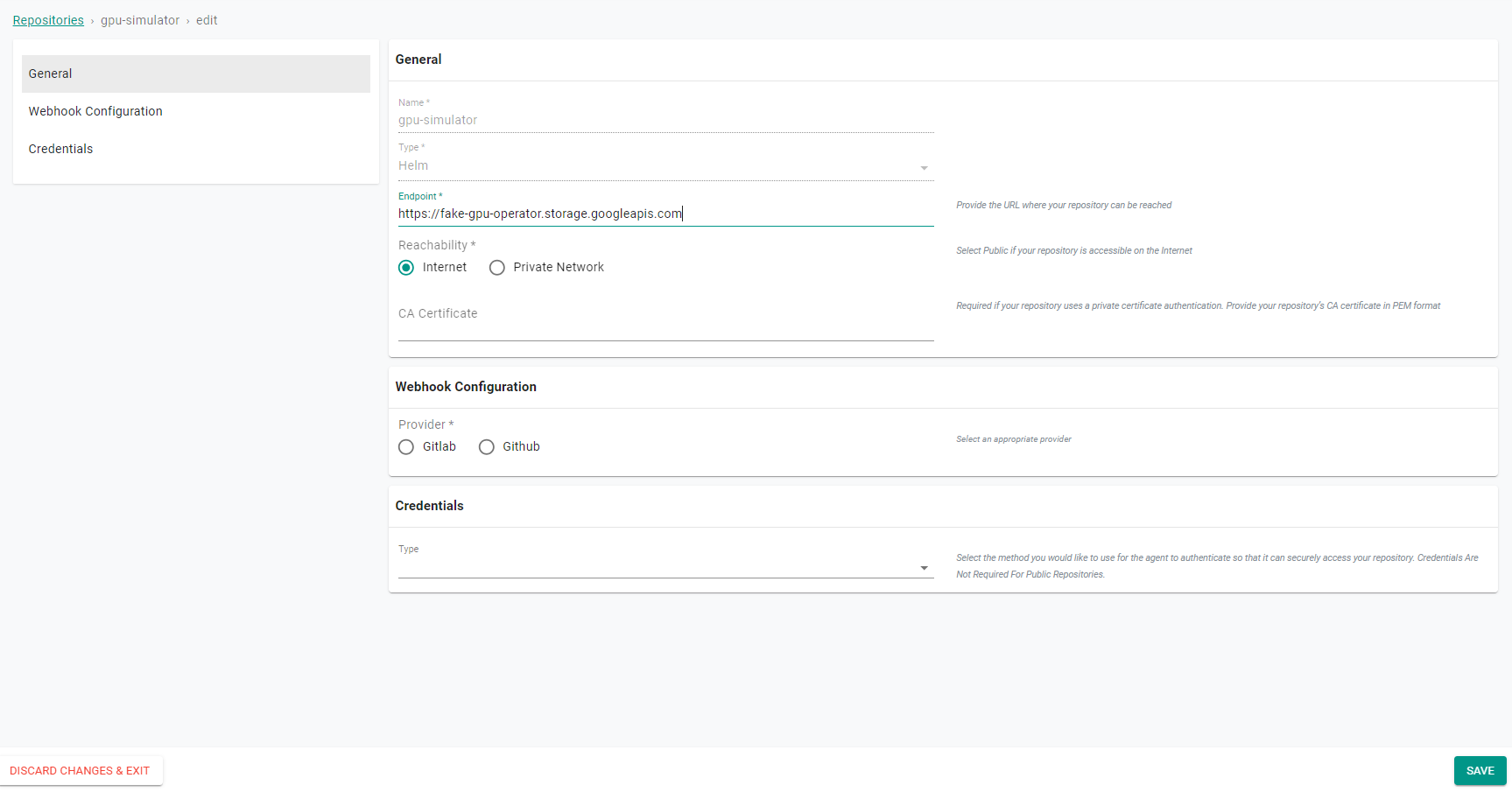
- Add the GPU Simulator Helm Chart repository URL: https://fake-gpu-operator.storage.googleapis.com in the Endpoint and save it.
Step 2: Create GPU Simulator Namespace¶
Create namespace on the cluster for installing the GPU Simulator in.
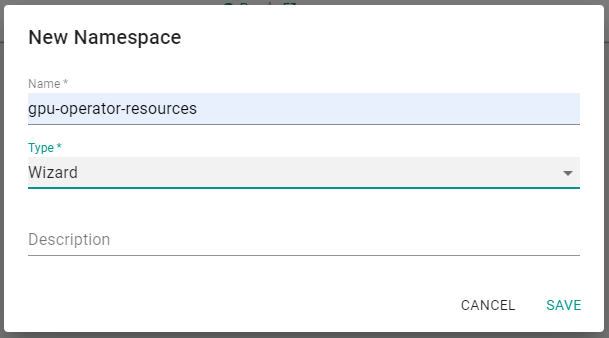
- Under Infrastructure, select Namespaces and create a new namespace with name
gpu-operator-resources.
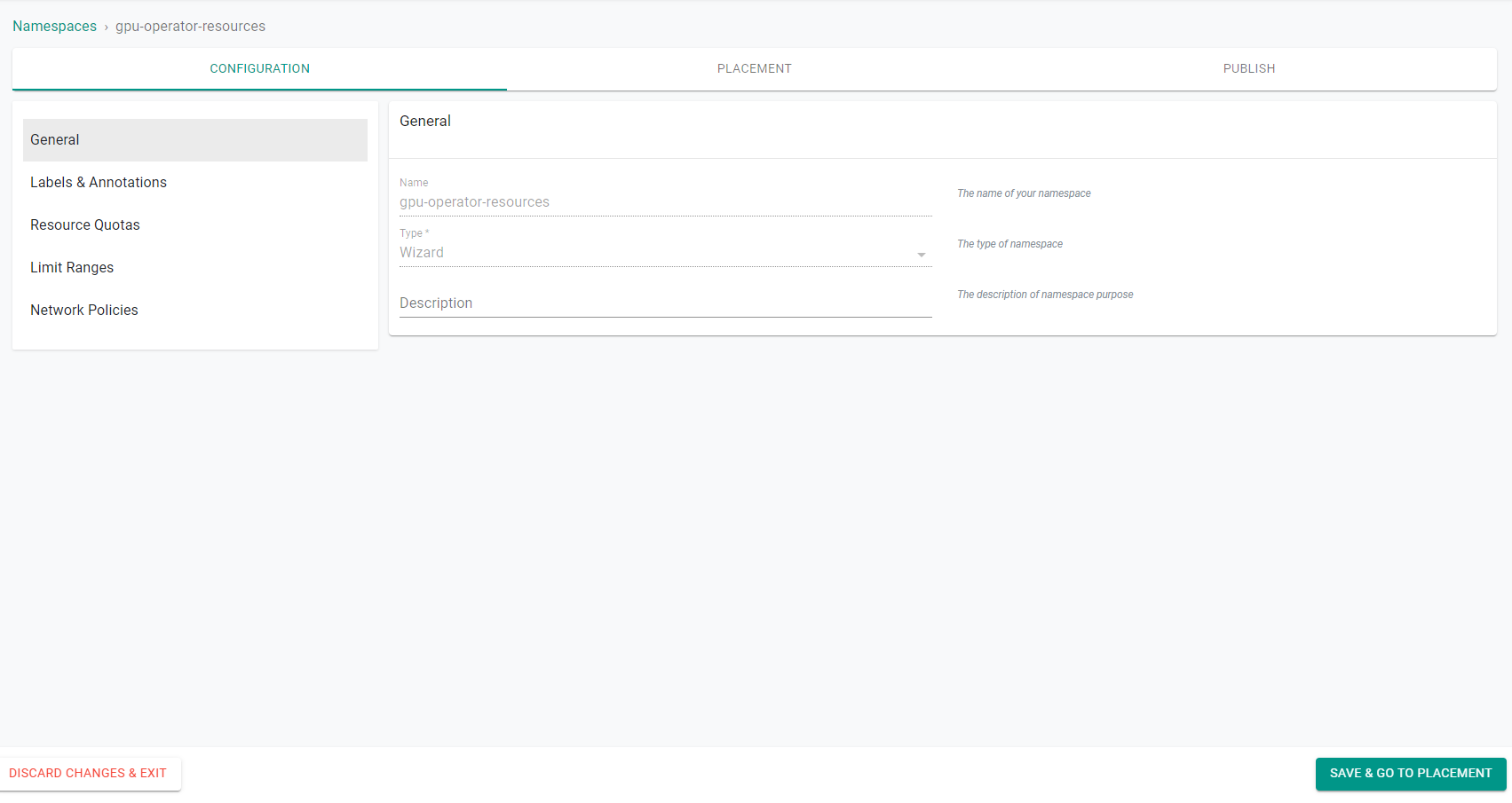
- Click Save and go to placement.
- Select the target cluster from the list of available clusters and click Save and go to publish.
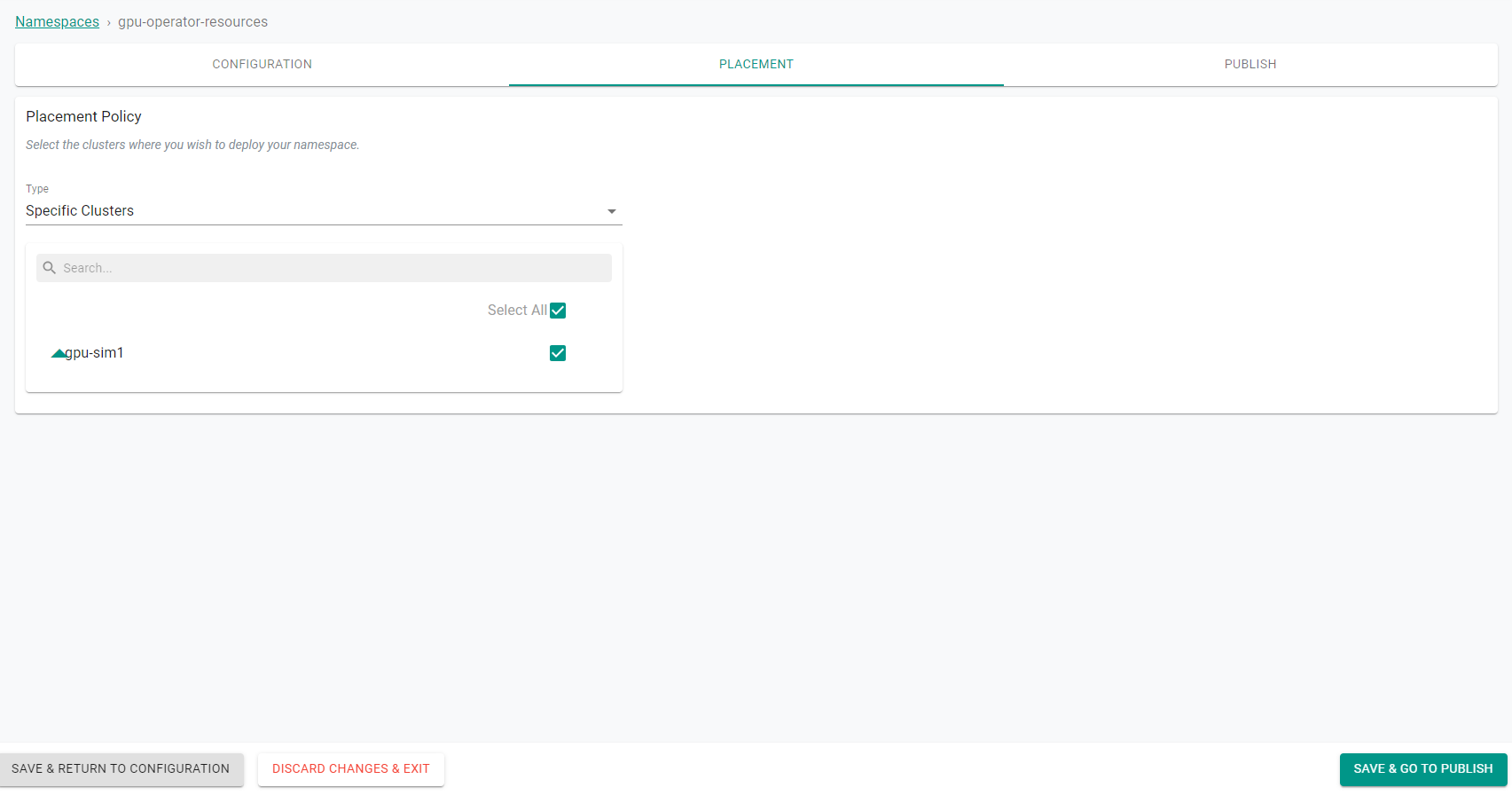
- Publish the namespace and make sure that it gets published successfully in the target cluster before moving to the next step.
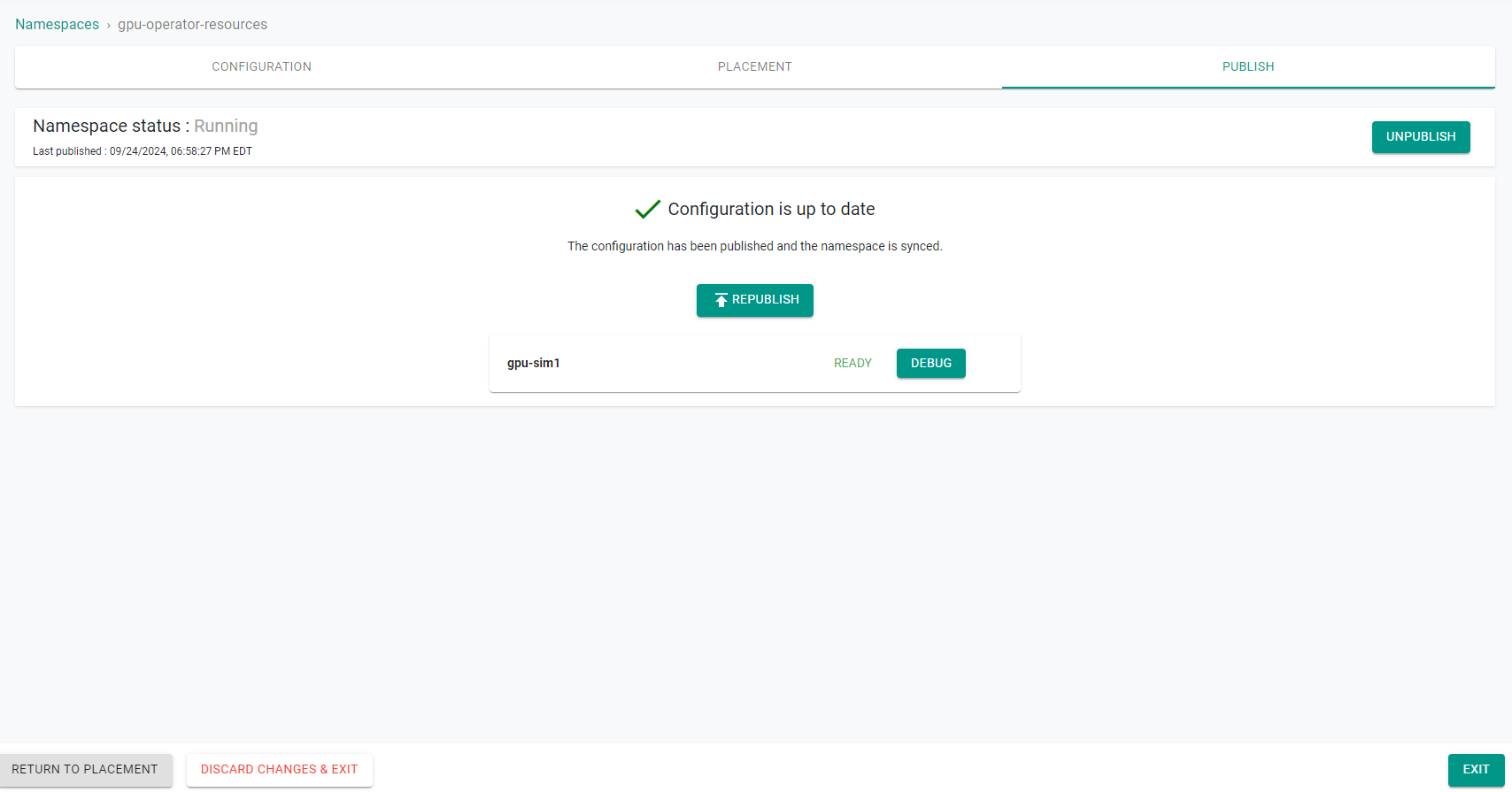
Step 3: Assign GPUs to Nodes¶
You can assign GPUs to nodes by applying a label to specific nodes. Run the following command being sure to update the node name and the node pool name.
kubectl label node <node-name> run.ai/simulated-gpu-node-pool=<node-pool-name>
Note
The node pool names are defined in the values.yaml file used when deploying the workload. The options in the provided values.yaml file are A100, H100 and T400. Additional node pool groups can be added to the values.yaml file as needed.
Step 4: Deploy GPU Simulator¶
Create a Workload to deploy the GPU Simulator Operator onto the cluster.
-
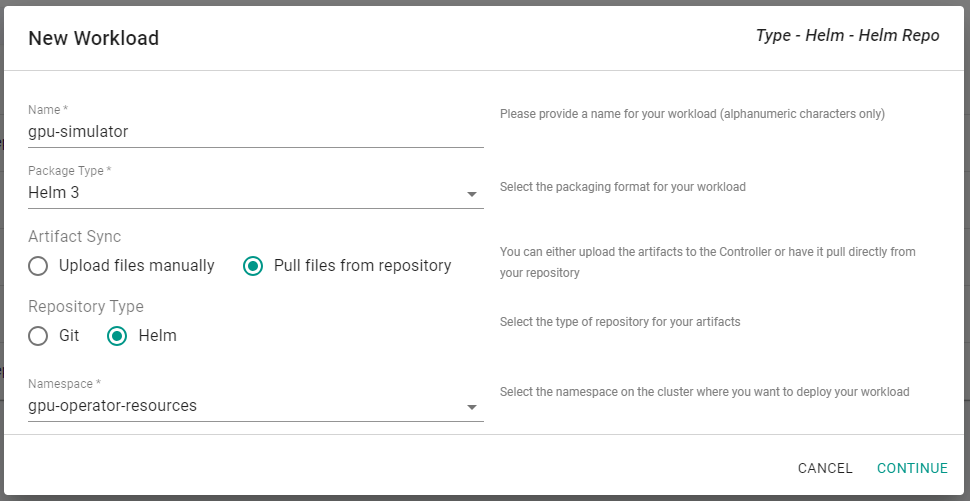
Under Applications, select Workloads and create a new workload with the name
gpu-simulator. -
Ensure that you select
Helm 3for Type,Pull files from repositoryfor Artifact Sync,Helmfor Repository Type and select the namespacegpu-operator-resources.
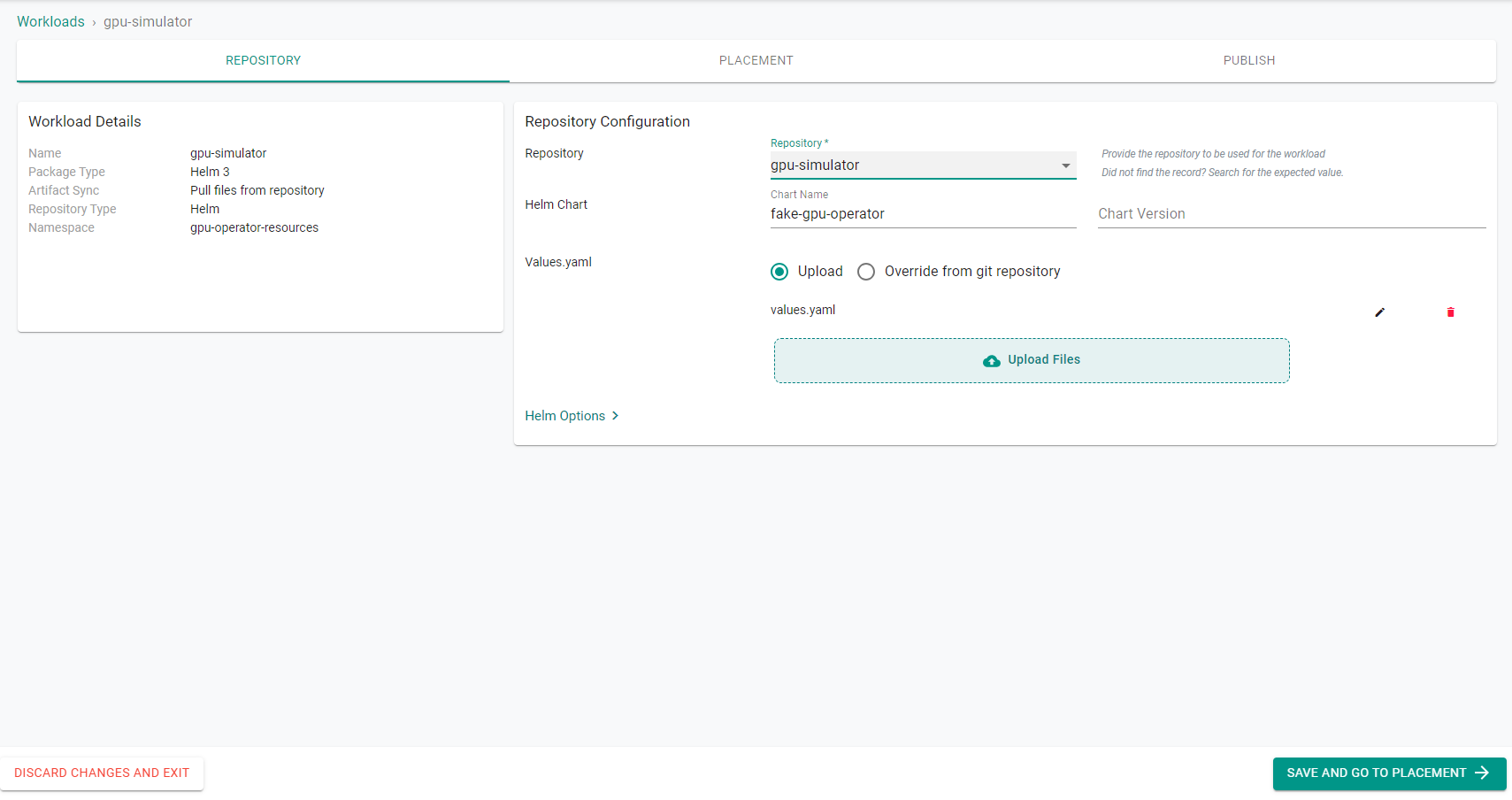
- Select the
gpu-simulatorRepository - Enter
fake-gpu-operatorfor the Chart Name - Create a YAML file named
values.yamlwith the following YAML:
topology:
# nodePools is a map of node pool name to node pool configuration.
# Nodes are assigned to node pools based on the node pool label's value (key is configurable via nodePoolLabelKey).
#
# For example, nodes that have the label "run.ai/simulated-gpu-node-pool: default"
# will be assigned to the "default" node pool.
nodePools:
A100:
gpuProduct: NVIDIA-A100
gpuCount: 4
H100:
gpuProduct: NVIDIA-H100
gpuCount: 4
T400:
gpuProduct: NVIDIA-T400
gpuCount: 4
- Upload the
values.yamlin the workload and Save and Go To Placement.
- Select the target cluster from the list of available clusters and click Save and go to publish.
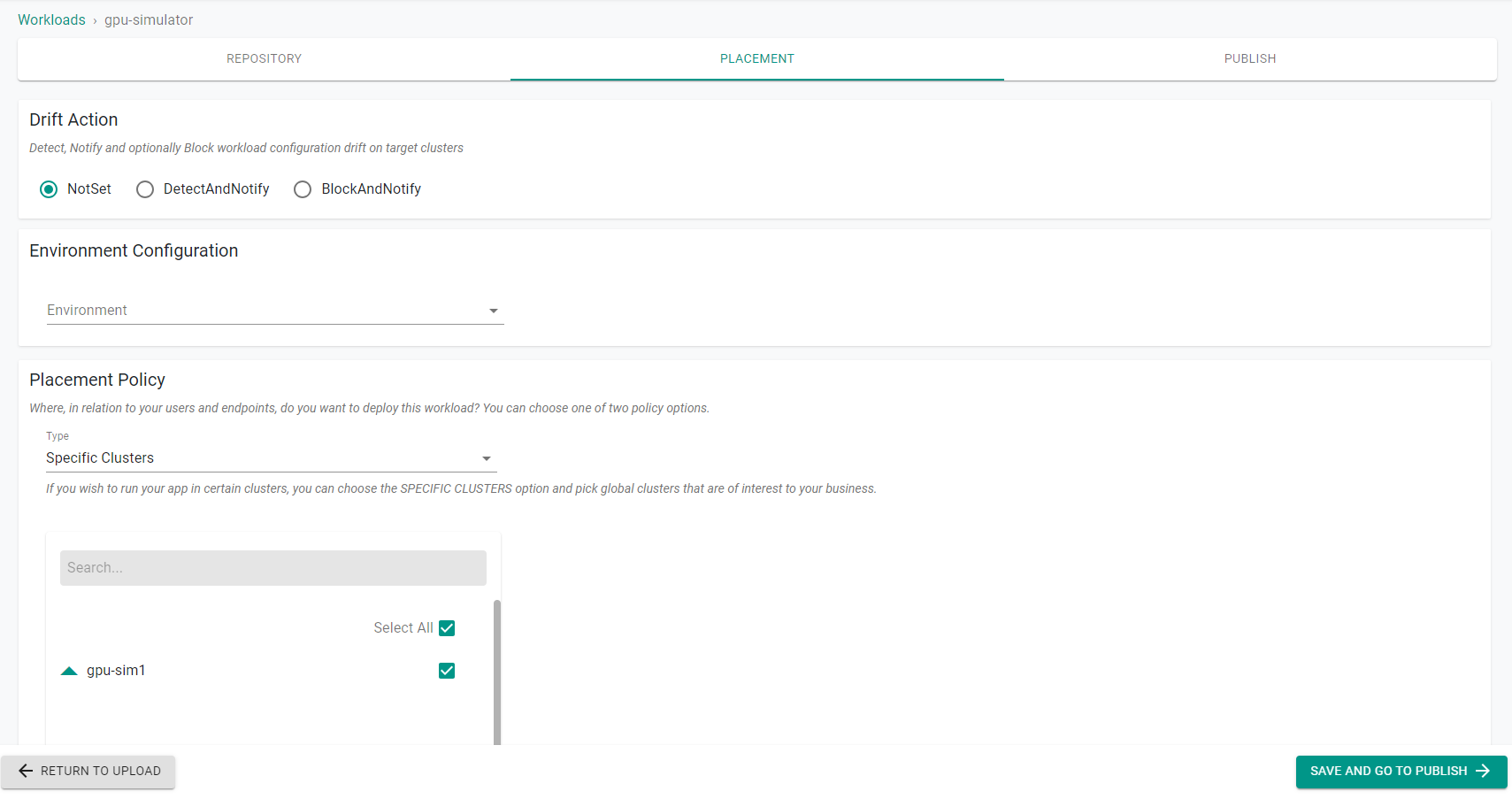
- Publish the workload and make sure that it gets published successfully in the target cluster before moving to the next step.
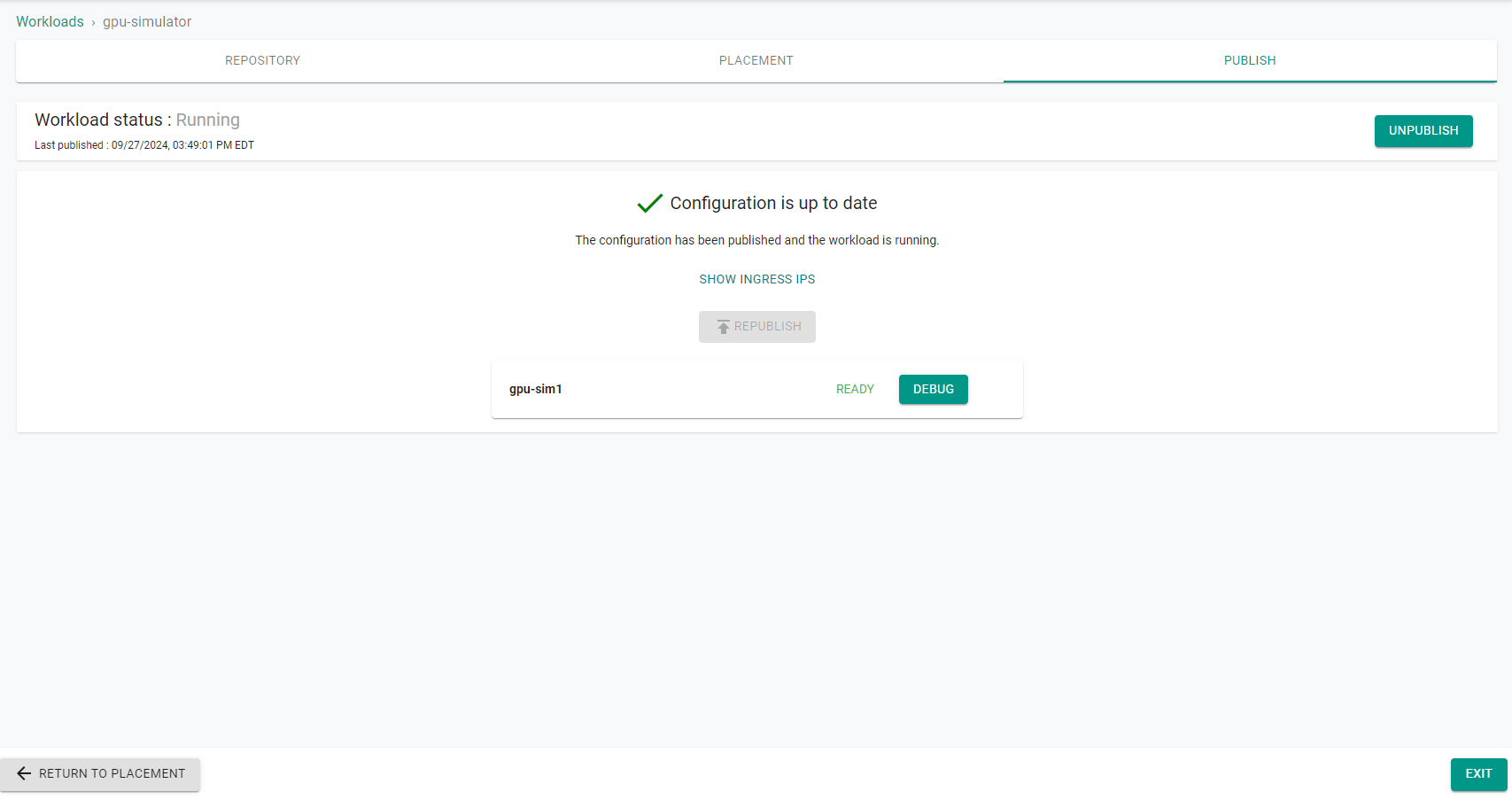
Step 5: Verify Deployment¶
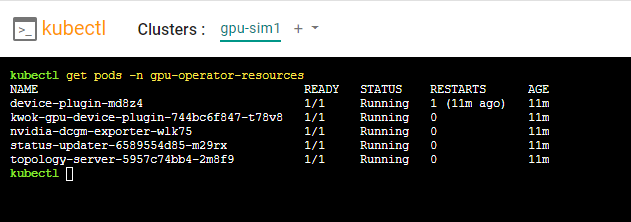
You can verify whether the resources related to GPU Simulator are properly deployed in the cluster.
- Click on the Kubectl web shell.
- Verify the GPU Simulator Operator deployment is up and running using the following command:
kubectl get pods -n gpu-operator-resources
Step 6: Deploy Test Application¶
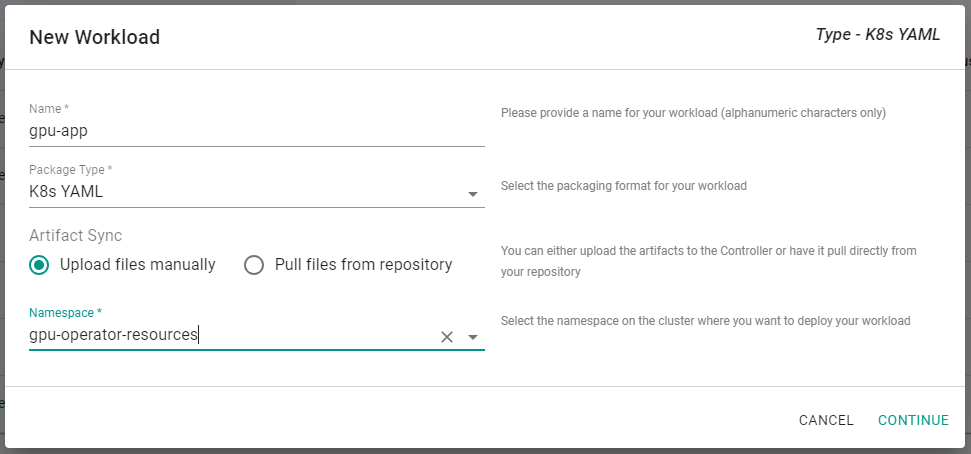
- Under Applications, select Workloads, then create a New Workload with the name
gpu-app. - Set Package Type to
k8s YAML - Select the Namespace as
gpu-operator-resourcesand - Click CONTINUE.
- Create a YAML file named
gpu-app.yamlwith the following YAML:
apiVersion: apps/v1
kind: Deployment
metadata:
name: sleepy-deployment
labels:
app: sleep
spec:
selector:
matchLabels:
app: sleep
replicas: 2
strategy:
rollingUpdate:
maxSurge: 25%
maxUnavailable: 25%
type: RollingUpdate
template:
metadata:
labels:
app: sleep
spec:
containers:
- name: sleep
image: alpine
command: ["sleep", "3600"]
imagePullPolicy: IfNotPresent
resources:
limits:
nvidia.com/gpu: 1
restartPolicy: Always
Take note that the application uses the GPU with the following lines:
resources:
limits:
nvidia.com/gpu: 1
- Upload the
gpu-app.yamlthat was created before and then go to the placement of workload.
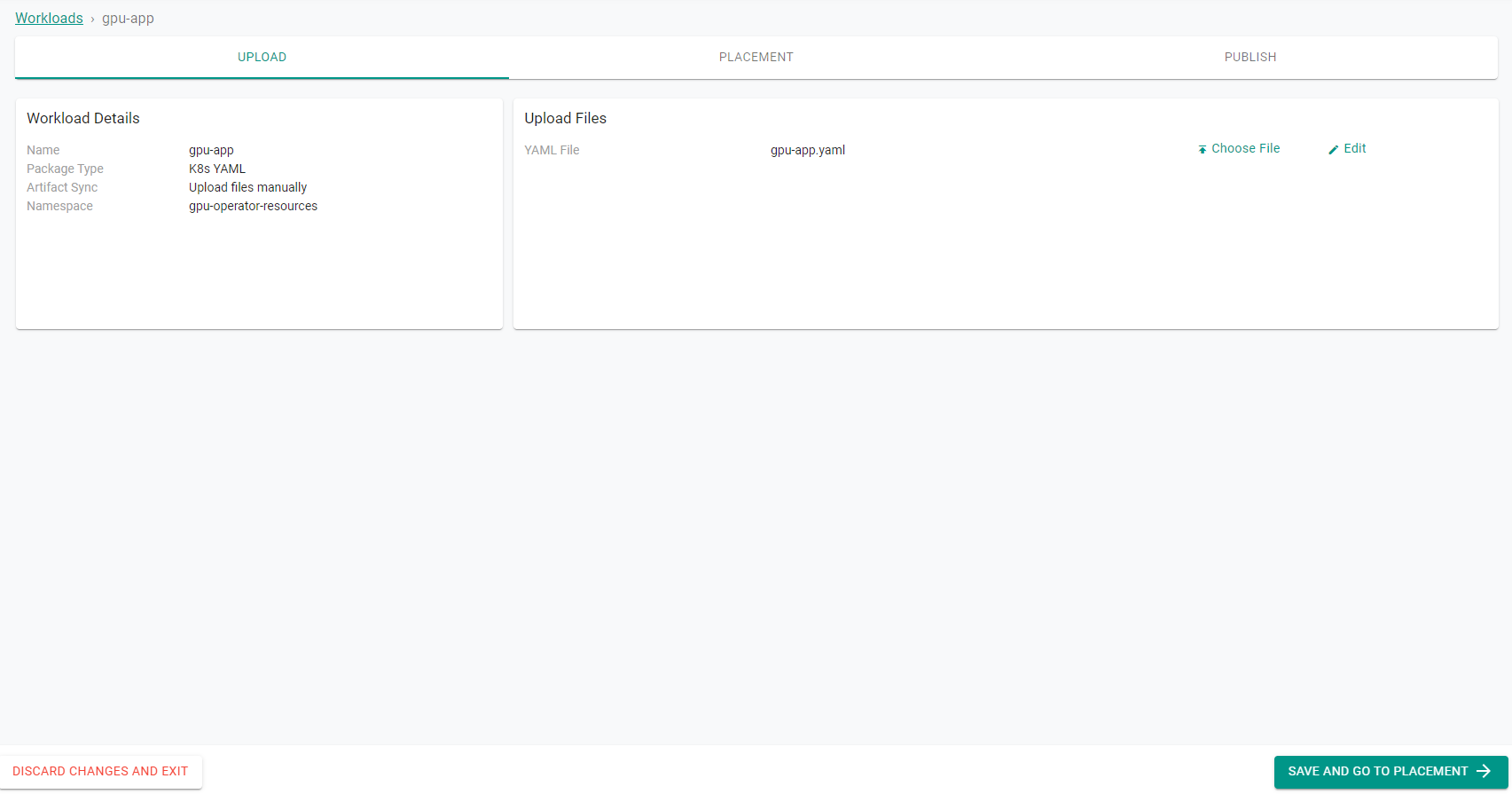
- Select the target cluster from the list of available clusters and click Save and go to publish.
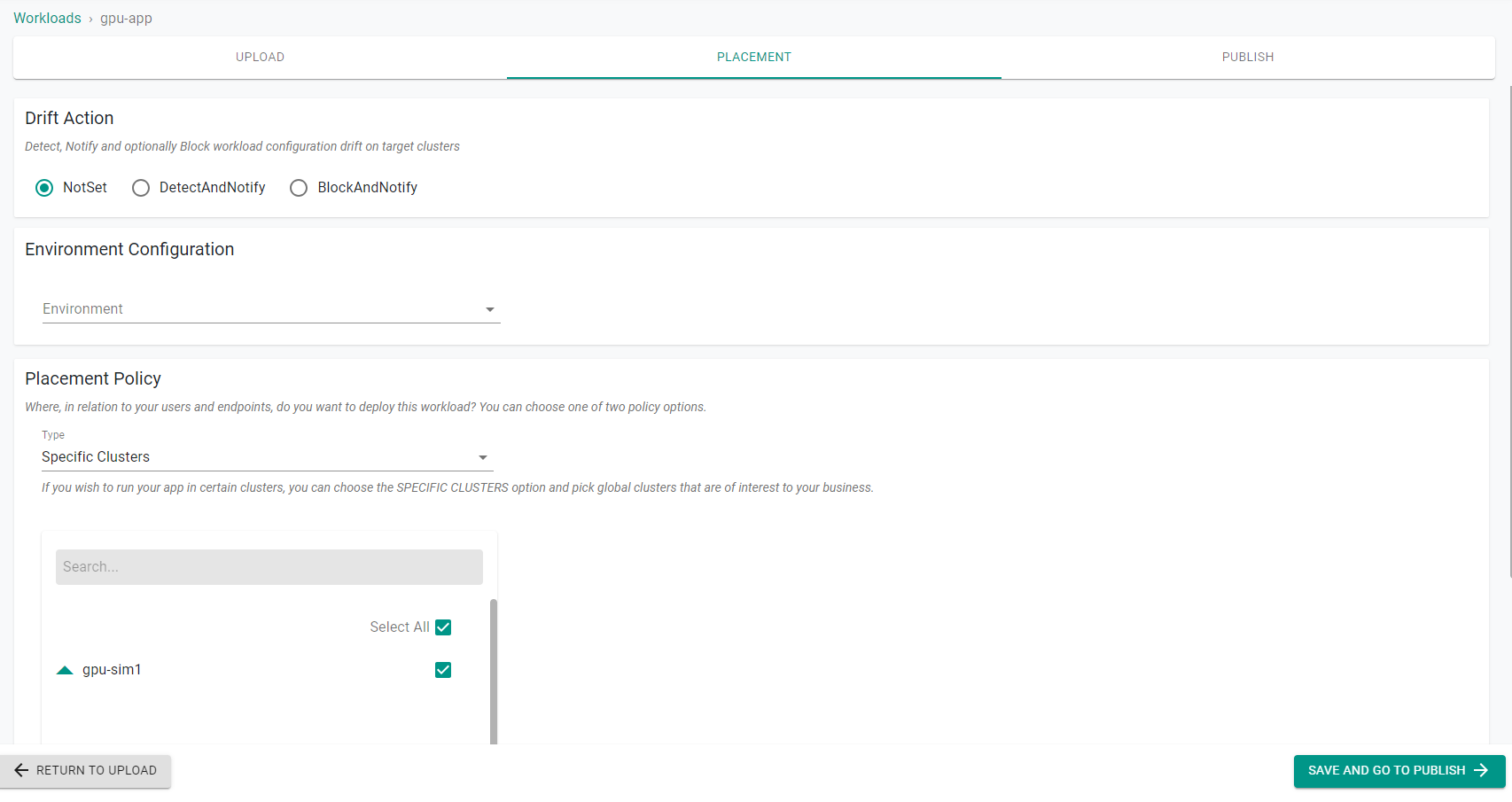
- Publish the workload and make sure that it gets published successfully in the target cluster before moving to the next step.
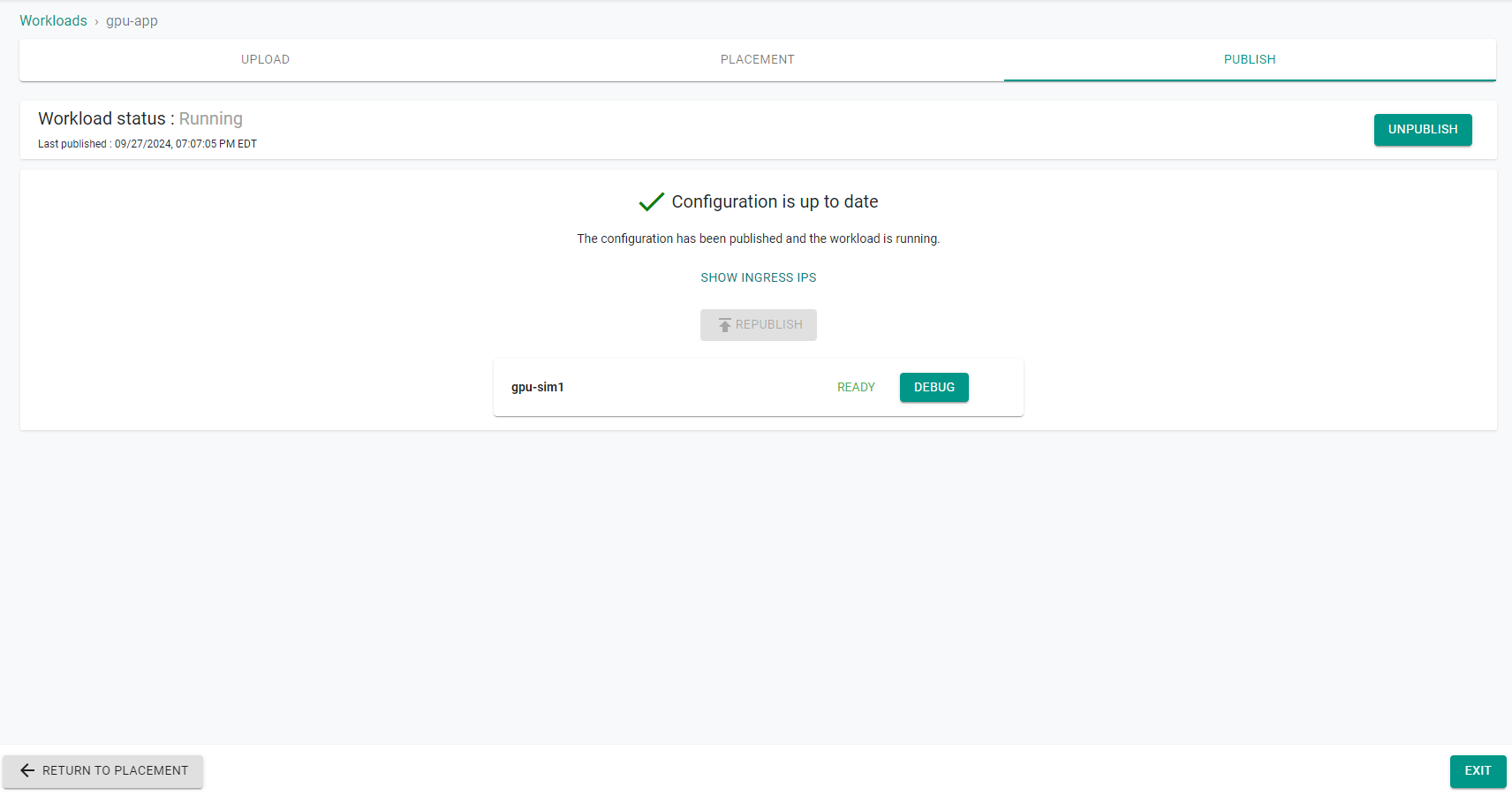
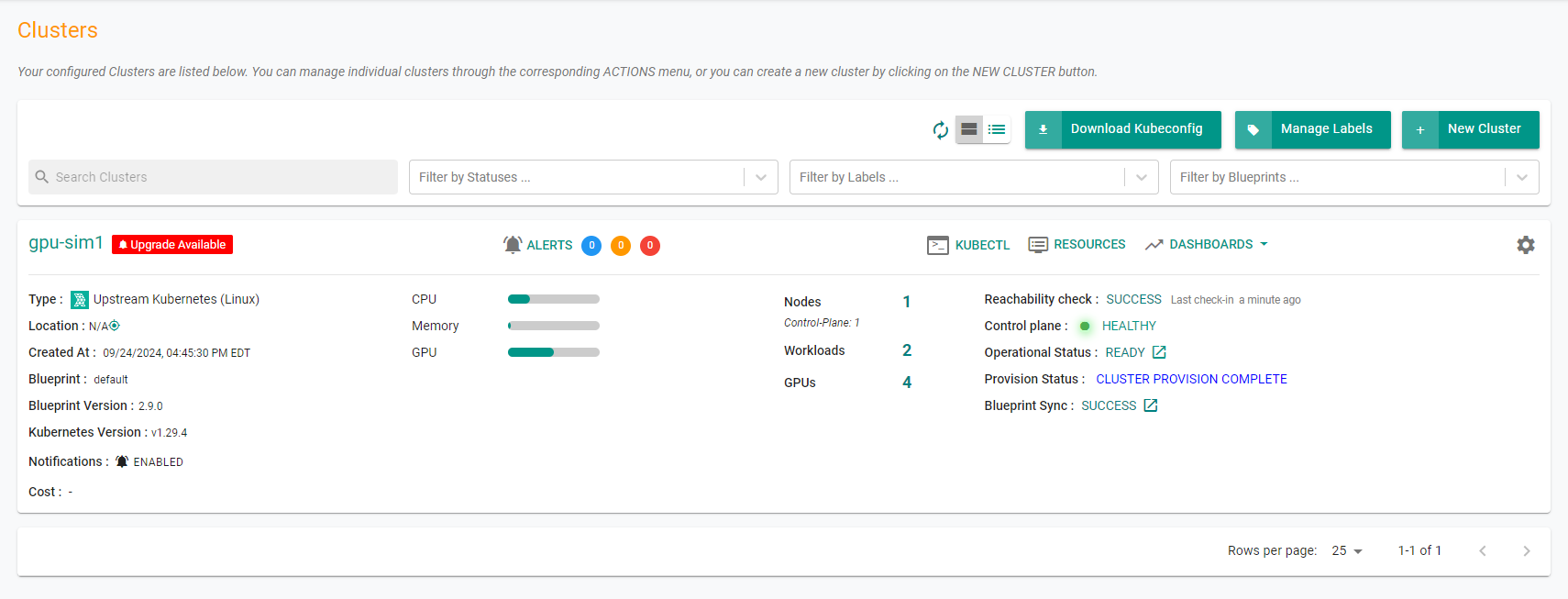
Step 7: Verify GPUs¶
After deploying application in the cluster, let us verify that Kubernetes cluster is allocating the "simulated GPU" as requested by the workload.
- Under Infrastructure, select Clusters
- View the GPU information in the cluster card showing the number of GPUs in the cluster and the number of GPUs currently consumed by applications
Recap¶
Congratulations! Now, you have successfully deployed the GPU Simulator in a cluster to simulate GPUs running in the cluster.