Troubleshooting
Cluster provisioning will fail if issues are detected and cannot be automatically overcome. When this occurs, the user is presented with an error message on the Web Console with a link to download the "error logs".
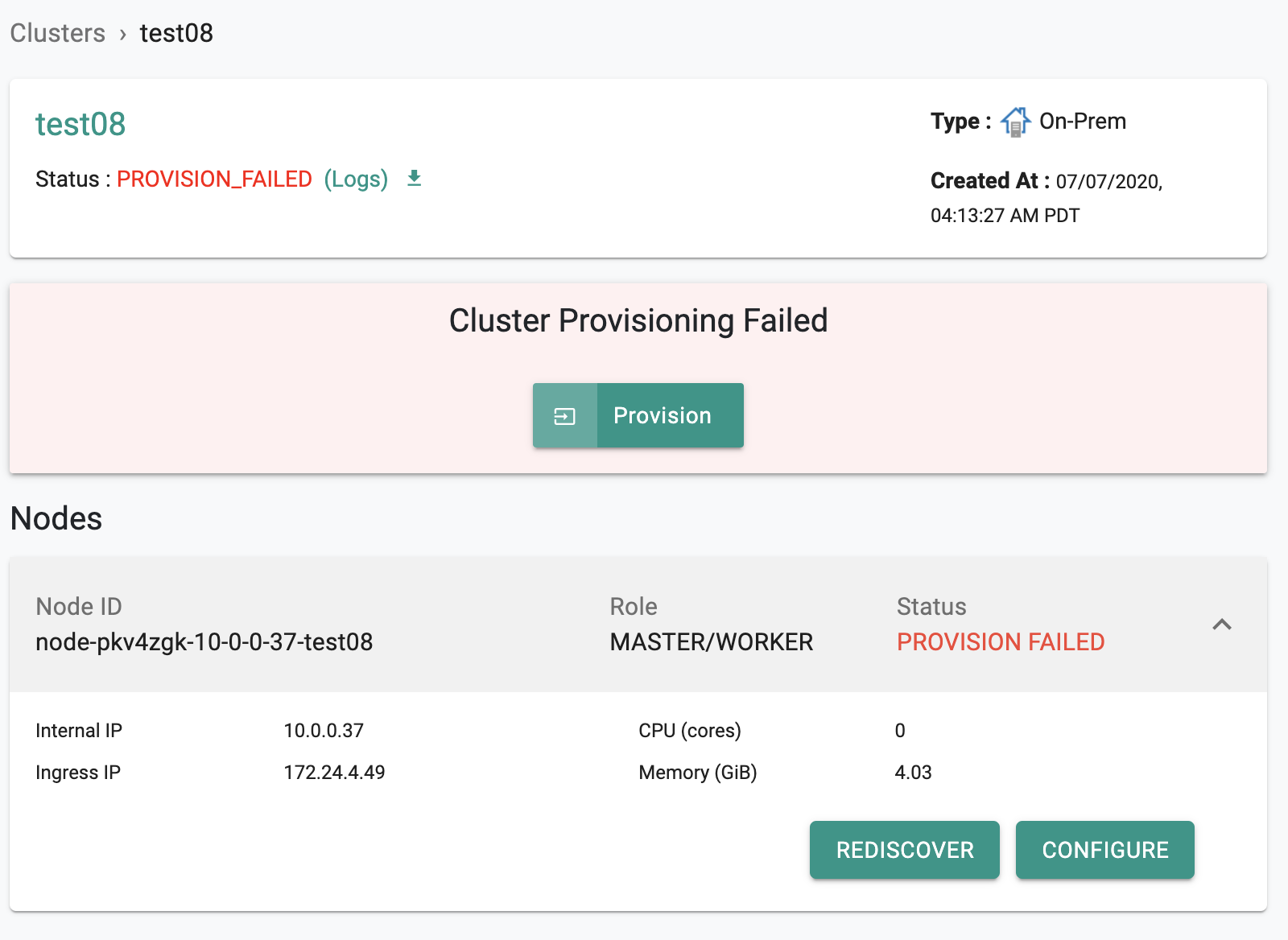
Environmental¶
Environmental or misconfiguration issues can result in provisioning failures. Some of them are documented below.
The platform provides tooling for "pre-flight" checks on the nodes before initiating provisioning. These pre-flight checks are designed to quickly detect environmental or misconfiguration issues that will result in cluster provisioning issues.
Important
Please initiate provisioning ONLY after the pre-flight checks have passed successfully.
RCTL CLI¶
Users that are using the RCTL CLI with declarative cluster specifications for cluster provisioning and lifecycle management may encounter errors that will be presented by RCTL. Some of the commonly encountered issues are listed below
Credentials Upload¶
This occurs when the RCTL CLI is unable to secure copy the credentials and the conjurer binary to the remote node(s).
./rctl apply -f singlenode-test.yaml
{
"taskset_id": "lk5owy2",
"operations": [
{
"operation": "ClusterCreation",
"resource_name": "singlenode-test1",
"status": "PROVISION_TASK_STATUS_PENDING"
},
{
"operation": "BlueprintSync",
"resource_name": "singlenode-test1",
"status": "PROVISION_TASK_STATUS_INPROGRESS"
}
],
"comments": "The status of the operations can be fetched using taskset_id",
"status": "PROVISION_TASKSET_STATUS_PENDING"
}
Downloading Installer And Credentials
Copying Installer and credentials to node: 35.84.184.226
scpFileToRemote() failed, err: failed to dial: dial tcp 35.84.184.226:22: connect: operation timed out%
Incorrect SSH Details¶
Provisioning will fail if incorrect SSH details are specified in the cluster specification file.
Error: Error performing apply on cluster "vyshak-mks-ui-test1": server error [return code: 400]: {"operations":null,"error":{"type":"Processing Error","status":400,"title":"Processing request failed","detail":{"Message":"Active Provisioning is in progress, cannot initiate another\n"}}}
Incorrect Node Details¶
Provisioning will fail if incorrect node details are specified in the cluster specification file.
Error: Error performing apply on cluster "vyshak-singlenode-test1": server error [return code: 400]: {"operations":null,"error":{"type":"Processing Error","status":400,"title":"Processing request failed","detail":{"Message":"Cluster with name \"vyshak-singlenode-test1\" is partially provisioned\n"}}}
Managed Storage¶
The customers using the rook-ceph storage node must deploy the default-upstream blueprint to the cluster.
Step 1: Verify Blueprint Sync¶
The rook-ceph storage is provided as an add-on with default-upstream blueprint, thus users can verify the rook-ceph managed storage deployment using the blueprint sync icon. Refer Update Blueprint to know more about update blueprint sync status
Step 2: Verify Health of Pods¶
On successful blueprint sync, users can view the rook-ceph pods running as shown in the below example:
kubectl -n rook-ceph get pod
11NAME READY STATUS RESTARTS AGE
12csi-cephfsplugin-4r8c5 3/3 Running 0 4m1s
13csi-cephfsplugin-provisioner-b54db7d9b-mh7mb 6/6 Running 0 4m
14csi-rbdplugin-6684r 3/3 Running 0 4m1s
15csi-rbdplugin-provisioner-5845579d68-sq7f2 6/6 Running 0 4m1s
16rook-ceph-mgr-a-f576c8dc4-76z96 1/1 Running 0 3m8s
17rook-ceph-mon-a-6f6684764f-sljtr 1/1 Running 0 3m29s
18rook-ceph-operator-75fbfb7756-56hq8 1/1 Running 1 17h
19rook-ceph-osd-0-5c466fd66f-8lsq2 1/1 Running 0 2m55s
20rook-ceph-osd-prepare-oci-robbie-tb-mks1-b9t7s 0/1 Completed 0 3m5s
21rook-discover-5q2cq 1/1 Running 1 17h
Node Debug Log Connectivity Issues¶
If a node is not connected or unhealthy, debug logs cannot be retrieved. In such cases, the UI displays the following message:
Node is not healthy. Please check and restart control services on the node. Details on how to do are available at (URL)

Restart Control Services
To re-establish connectivity between the node and the controller, restart the control services. Depending on your environment, use the following commands:
systemctl restart salt-minion-rafay
systemctl restart chisel-rafay
systemctl restart salt-minion
systemctl restart chisel
When to Use
- If the cluster is using Rafay-provided services, restart
salt-minion-rafayandchisel-rafay - If the cluster is running in a non-multi-minion environment, restart the standard
salt-minionandchiselservices.
Common Issues¶
Provisioning Challenges with Conjurer Preflight Tests¶
Although "conjurer" provides a built-in battery of "preflight tests" that can be used to verify the environment and configuration, there are some scenarios where provisioning can fail.
Host Firewall¶
If your instances (for the nodes) have a host firewall such as firewall or iptables rules, it may be silently drop all packets destined for the Controller. This will result in provisioning failure. Ensure that the host firewall is configured to allow outbound communications on tcp/443 to the controller.
Inter Node Communication¶
Ensure that the host firewall is configured to allow inter node communication so that pod's can reach to the api server
MTU¶
The Maximum Transmission Unit (MTU) is the largest block of data that can be handled at Layer-3 (IP). MTU usually refers to the maximum size a packet can be. Certain MTU/MSS settings can result in fragmentation related issues with mTLS connections between the agents and the controller.
Unstable Network¶
Unstable or unreliable network connectivity. Remote cluster provisioning in remote, low bandwidth locations with unstable networks can be very challenging. Review how the retry and backoff mechanisms work by default and how they can be customized to suit your requirements.
Cluster Provision/Upgrade Failures¶
When a cluster provision/upgrade or node addition to an exiting cluster fails, perform the below steps:
sshto faculty node where provision/upgrade/addition failed- Run
systemctl status salt-minion-rafayto check the minion status (active/inactive) - If the Salt minion is not active, restart it using the command
systemctl restart salt-minion-rafay - To check for any errors, verify the logs of the active minion from the file cat /opt/rafay/salt/var/log/salt/minion
Note
It will help the support team if you are able to zip the log files and share with them.
Connectivity Issues Between Pods and Kubernetes Apiserver in Multi-Node Setup¶
Failure Scenario
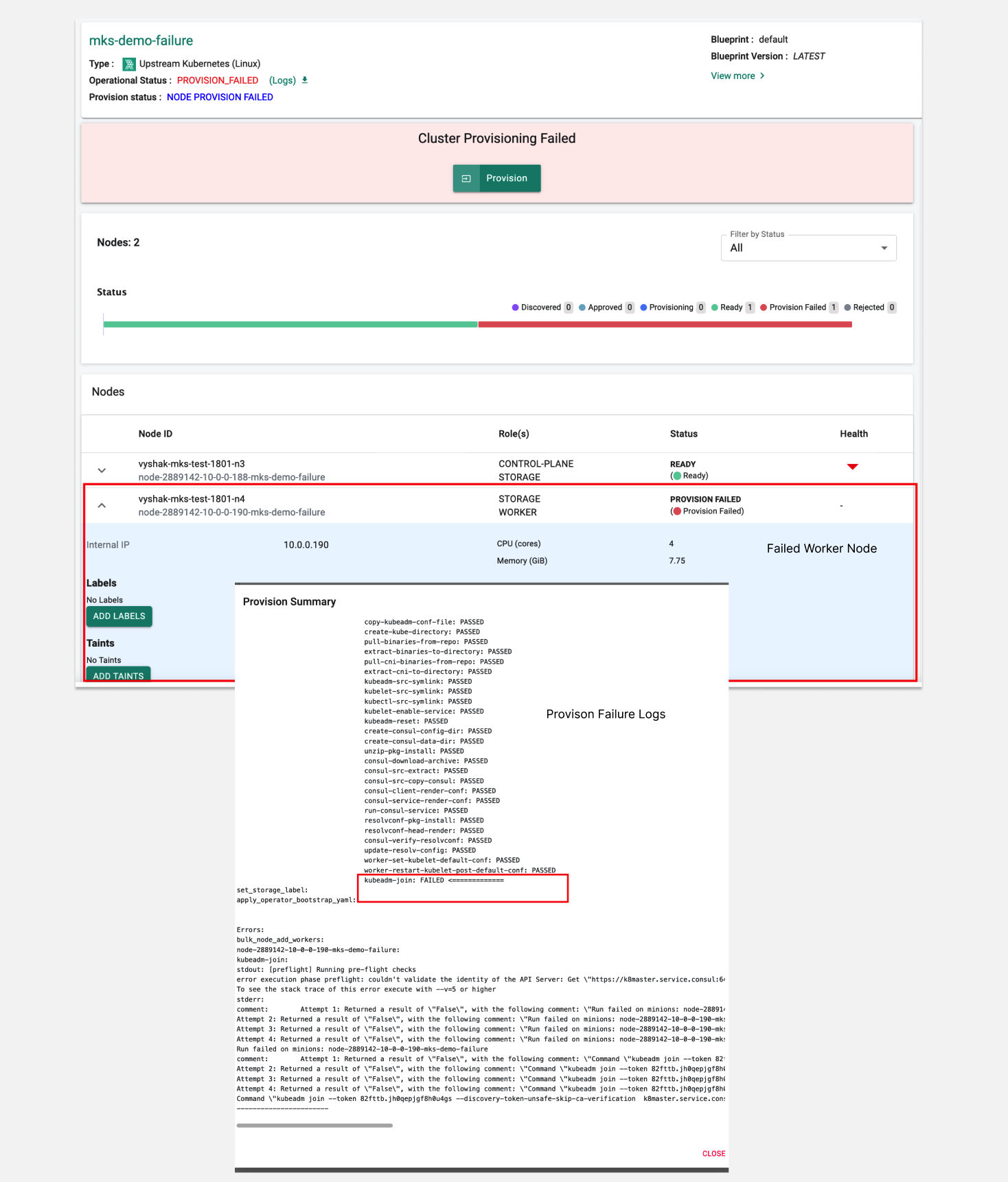
In a restricted environment, a common challenge arises when firewalld hinders Pods from reaching the apiserver. This can lead to failures during cluster provisioning or upgrades. If you encounter such issues, follow these troubleshooting steps:
- Inspect the container logs of the affected Pods to identify any errors. Execute the command:
kubectl logs <pod-name> -
Check the status of firewalld on your machine using the following commands:
Ensure that firewalld is appropriately configured to allow inter-node communication in a multi-node setup, enabling Pods to reach the api server. If you encounter issues and suspect that firewalld might be causing the problem, you can temporarily stop and disable it using the following commands:sudo systemctl status firewalldAfter stopping and disabling firewalld, check if the connectivity issues persist. If the problem is resolved, you may need to adjust the firewalld configuration to allow the necessary communication between your pods on worker node to Kubernetes API server pod on the master .sudo systemctl stop firewalld sudo systemctl disable firewalld -
Investigate potential issues with iptables. As a troubleshooting step, attempt to resolve it by clearing out iptables using the command:
iptables -F - Check the minion logs for debugging purposes. The minion logs are located at /opt/rafay/salt/var/log/salt/minion. In case of connectivity failures, the logs might indicate the node's inability to connect to the master node. A sample failure scenario in the logs could resemble the following:
If you encounter such entries, consider investigating firewall settings, network configurations, or any other connectivity issues that might be hindering the communication between nodes in your Kubernetes cluster.
error execution phase preflight: couldn't validate the identity of the API Server: Get "https://k8master.service.consul:6443/api/v1/namespaces/kube-public/configmaps/cluster-info?timeout=10s": dial tcp: lookup k8master.service.consul on 127.0.0.53:53: no such host
Connectivity Issues Between Node and Rafay Controller¶
Ensure whitelisting in place in your datacenter’s firewall to allow the hosts to make outbound TLS (port 443) connection to Rafay.
Whitelisting IP/FQDN to our controller can be found here.
Pods on different nodes are not able to communicate together¶
Pods on different nodes might experience communication failures for two reasons. First, a firewall could be blocking the communication. Second, there could be a discrepancy in the Maximum Transmission Unit (MTU) values between worker and master nodes. MTU is like the maximum size of a message that can be sent.
To address these communication issues:
-
Check for firewalls: Verify that no firewalls are preventing pods from communicating across nodes.
-
Verify MTU consistency: Compare the MTU values on worker and master nodes. Ensure that the MTU configuration on the network interfaces of both types of nodes is accurate and consistent. This will help ensure smooth communication between pods.
Log Rotation on Nodes¶
To prevent nodes from running out of disk space due to growing log files, a log rotation strategy is applied.
- Only the last 100 MB of logs are retained.
- Older content is archived into tar files.
- The system keeps only the last five 100 MB files on a node.
- When a new file is added, the oldest file is deleted automatically.
This approach helps manage disk usage effectively without impacting recent log availability.
Resolving Intermittent Worker Node Down During MKS Cluster Upgrade¶
If you encounter intermittent failures during a Kubernetes (MKS) Cluster upgrade with a message indicating that the worker node is down, follow these steps:
1 Status of control channel for <Node_name>: Down
2 Status of control channel for <Node_name>: Up
3 Status of control channel for <Node_name>: Up
4 Status of control channel for <Node_name>: Up
Run the following commands on the MKS cluster node that is down:
$ systemctl restart salt-minion-rafay
$ systemctl restart chisel.service
This should resolve the issue and allow you to proceed with the upgrade.
Error During Node Addition in the Cluster When running Conjurer¶
If you encounter the following error while running Conjurer during the process of adding a node to the cluster:
!ERROR! Failed to detect Operating System. None
Ensure that the Operating System of the machine where Conjurer is executed is supported. Refer to the list of supported OS here
Cluster Provisioning Fails - Node Not Found¶
stderr: Error from server (NotFound): nodes \"$NODE_NAME\" not found
This error is triggered when a node hostname contains an invalid character. According to Kubernetes naming conventions, the node name must adhere to certain rules .
To resolve this issue, recreate the node with a valid hostname and then restart the provisioning process. Ensure the new hostname complies with Kubernetes naming guidelines
Worker Node in NotReady State¶
Scenario 1: Kubelet Service NOT running
If a worker node is observed to be in a NotReady state, it could be attributed to the kubelet service not running on the node. This scenario often arises when swap is enabled on the worker node.
To address this issue:
- Execute the following command to check the status of the kubelet service on the worker node:
sudo systemctl status kubelet
If the status is NotReady, determine if swap is enabled on the worker node. If swap is active, it can hinder the proper functioning of the kubelet service.
- Disable swap and restart Kubelet service
It is recommended to ensure that swap is disabled on nodes within a Kubernetes cluster for optimal performance and reliability.
Scenario 2: Worker Node Communication with Master Nodes
Ensure that all required ports are accessible between both master and worker nodes.
To check whether the necessary ports between nodes are open, use the below command
nc -zv <IP>:<PORT>
If the worker node can reach the master node and the necessary ports are open, the command will execute successfully.
Refer Inter Node Communication for more information
Consul Member Unable to Rejoin After Node Reboot¶
After a node reboots it may try to rejoin the Consul cluster but existing members reject its vote attempts, so the node remains unable to rejoin. Resolving this typically requires clearing the affected node’s local Consul state so it can rejoin. To reduce recurrence, you can set the cluster-level label discovery-cleanup: disabled via Terraform or RCTL (supported for both Day 0 and Day 2).
Blueprint Switching in Cluster Provisioning¶
The below error occurs when the user switches from any blueprint to default-upstream after cluster provisioning if no storage role was added before cluster provisioning. Assume there is no storage attached to the node, and the cluster was created with a non-default-upstream BP, later switching to default-upstream BP. During this transition, BP sync may be in progress or fail.
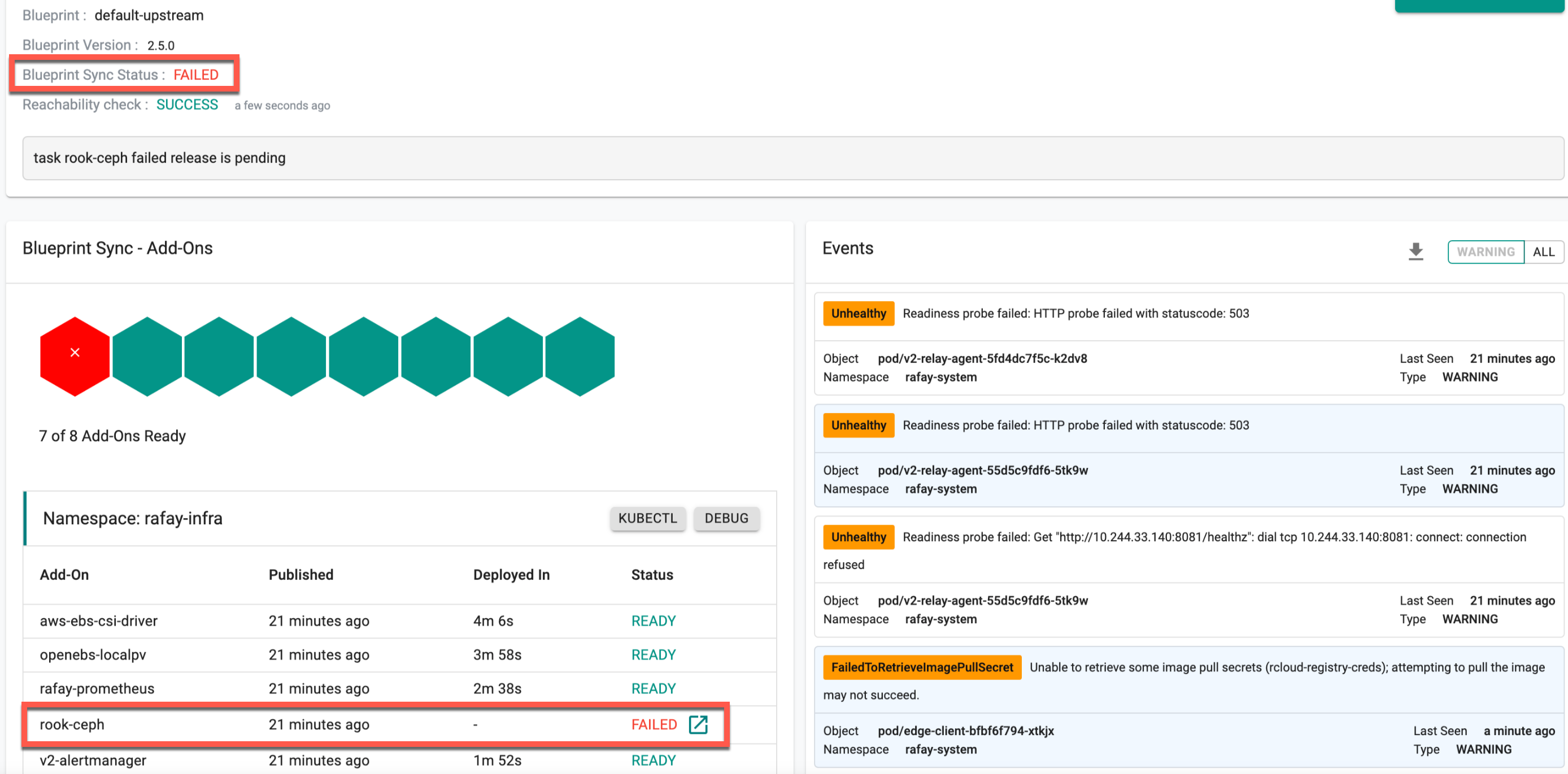
To overcome this scenario, perform the below steps:
- Switch back to the previous BP (any non-default-upstream BP) that was set during provisioning
- Navigate to the respective cluster and delete the rook-ceph related jobs using the command
kubectl delete job. If the cluster's rook-ceph deletion is still in progress in the UI, reapply the same BP (non-default-upstream BP) to ensure cleanup is completed - Now the user can update the node with the required storage labels and then update the BP to default-upstream. If updating the BP encounters issues, perform a cleanup and then retry the update
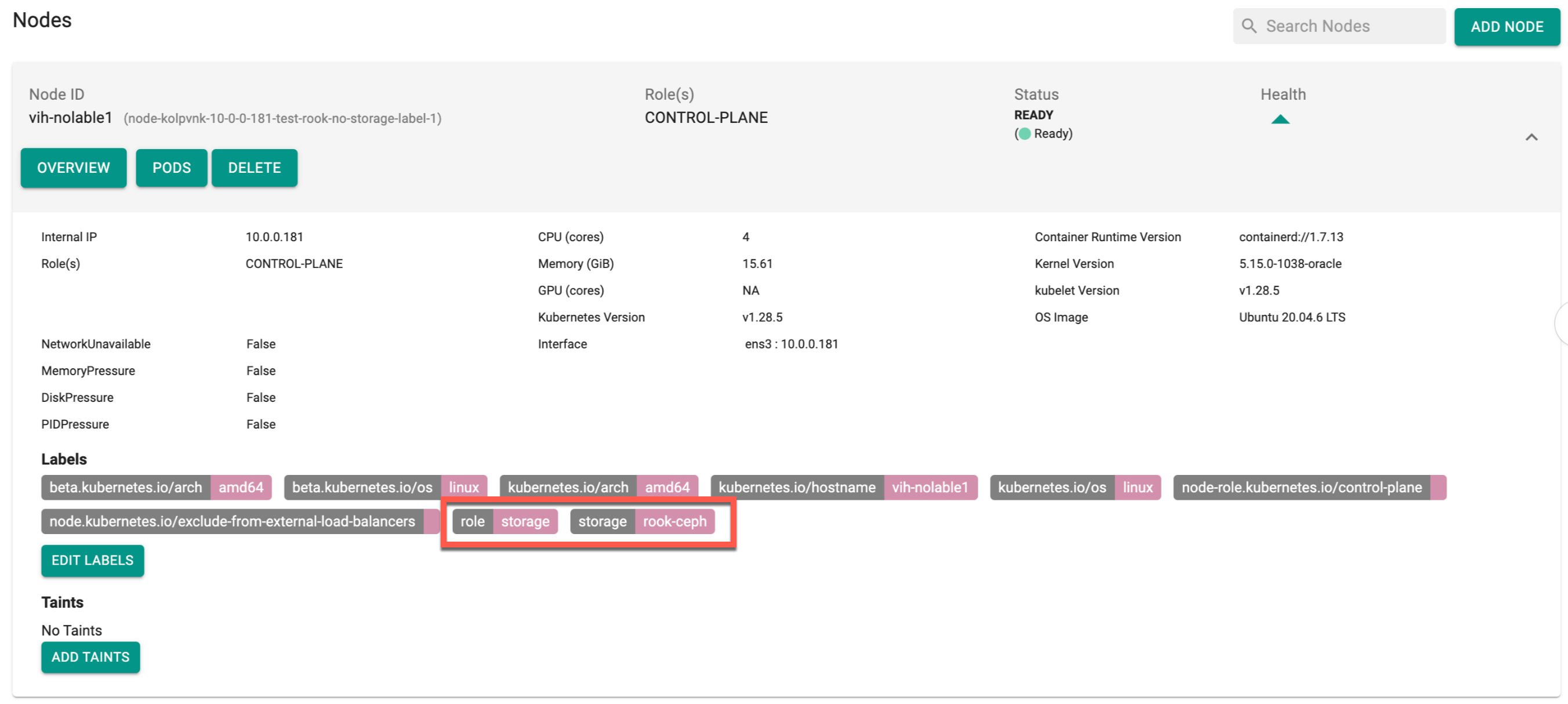
Note: In High Availability (HA) configuration, it is mandatory to have a minimum of 3 nodes, each of which must support storage roles for the successful installation of rook-ceph. Conversely, in a Non-HA configuration, atleast one node is mandatory with storage role.
Support¶
If you are unable to resolve the issue yourself, please contact Support or via the provided private Slack channel for your organization. The support organization is available 24x7 and will be able to assist you immediately.
Please make sure that you have downloaded the "error log file" that was shown during failure. Provide this to the support team for troubleshooting.
Remote Diagnosis and Resolution¶
For customers using the SaaS Controller, with your permission, as long as the nodes are operational (i.e. running and reachable), the support team can remotely debug, diagnose and resolve issues for you. Support will inform the customer if the underlying issue is due to misconfiguration (e.g. network connectivity) or environmental issues (e.g. bad storage etc).
Important
Support DOES NOT require any form of inbound connectivity to perform remote diagnosis and fixes.