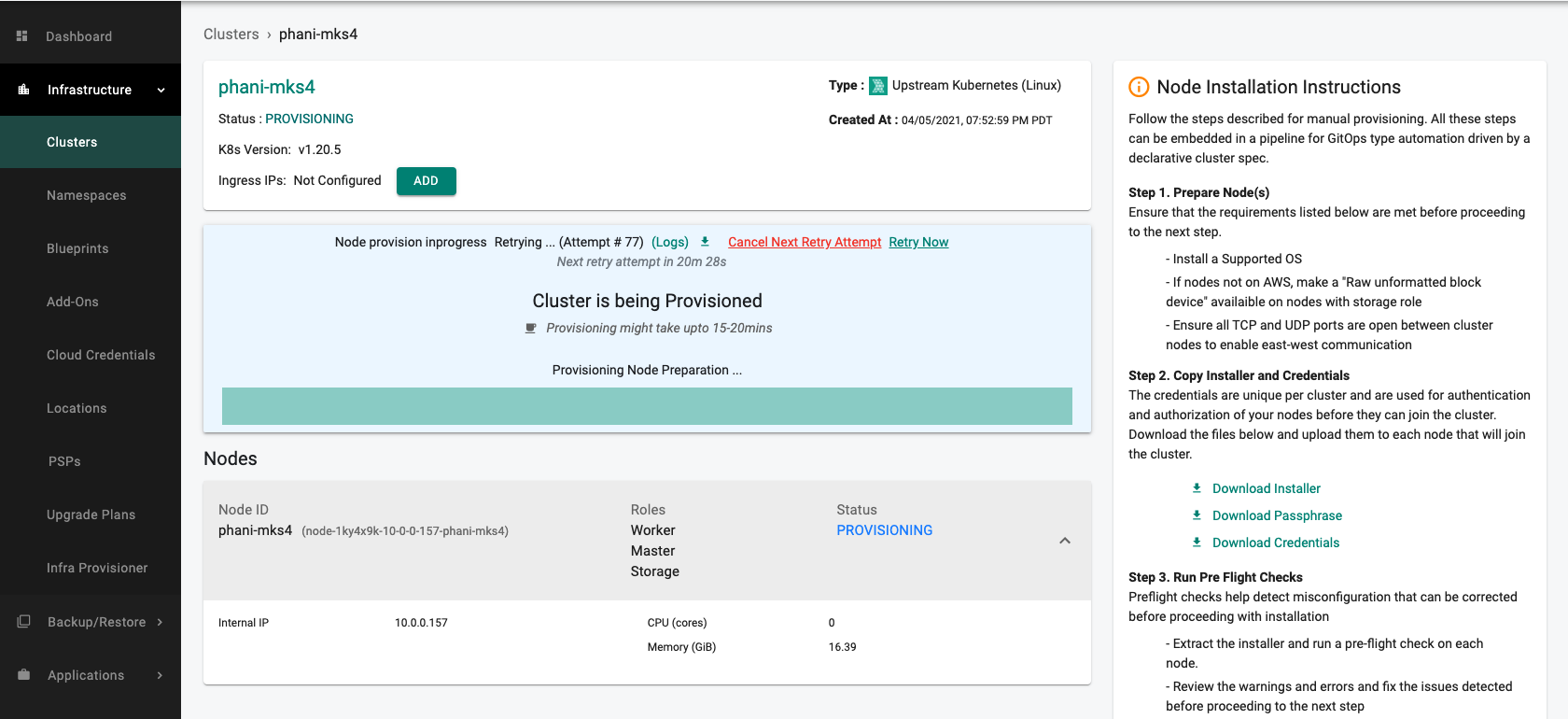
Retry and Backoff
Background¶
Remote provisioning of a production grade Kubernetes cluster is a time consuming activity. Multiple software components (spanning k8s, k8s mgmt operator, managed addons in cluster blueprint) need to be installed, sometimes in a specific sequence to ensure that the cluster is provisioned successfully.
With the pre-packaged virtual appliance form factor (qcow and ova images), a large portion of the components are available locally helping avoid the need to download multiple components one-by-one. With the pre-packaged virtual appliance images, the operating system is managed by the controller as well. Therefore, latest Operating System software packages, security patches also need to be downloaded from the controller to ensure that the entire tech stack is always provisioned with a solid security posture (i.e. software without known security vulnerabilities).
Downloading all these security updates etc during cluster provisioning requires fast and reliable network connectivity (i.e. reasonable bandwidth and a reliable network) to the controller. However, it is not always possible to guarantee this especially for "EDGE" clusters (e.g. remotely provision a Kubernetes cluster at a remote hospital or retail store).
The default retry timers in Kubernetes and the OS are not optimized for low bandwidth and unreliable network situations. As a result, if the network drops or if bandwidth issues are encountered during a cluster provisioning or expansion process, provisioning can fail. To overcome this issue, we provide our partners and customers options to tune and optimize the timers to suit their deployment scenarios.
Retry and Backoff¶
A combination of retry and backoff algorithms are used to help optimize the provision process. The controller provides the ability to customize and use a different set of retry and backoff timers for Upstream Kubernetes clusters that are remotely provisioned. These settings are applied at a "partner" level in the controller. All customer Organizations managed by the Partner will automatically inherit these settings.
Retry¶
- By default, "five retry attempts" are made before the process is categorized as a failure.
- The number of retry attempts is configurable "per partner"
- Please contact your support team to describe your requirements so that this setting can be configured and optimized for your specific use case.
- Although provisioning is retried automatically, the user has the option to cancel upcoming retry attempts (for e.g. the user already knows the network will be offline for days, node powered down for near term due to hardware issues)
- If cancelled, the current ongoing retry attempt will not be stopped but all upcoming attempts will be cancelled
- Users can also initiate a "retry now" if they wish to not wait for the backoff period (for e.g. the users knows that the network has been restored, node power up after maintenance etc)
- Users will be provided access to logs for the last-5 retry attempts in case they want to investigate the issue further
Backoffs¶
An exponential backoff algorithm is used before the next retry is attempted.
- By default, the backoff interval starts at 30 seconds and grows exponentially until a 60 min threshold is encountered and provisioning is deemed a failure.
- The backoff threshold time is configurable "per partner"
- Please contact your support team to describe your requirements so that this setting can be configured and optimized for your specific use case.
The table below describes some examples of "retry attempts" mapped to "wait time" for provisioning.
| Backoff Time | Number of Retries |
|---|---|
| 1 Day | 58 |
| 1 Week | 196 |
| 1 Month | 669 |
| 1 Year | 7,561 |