InfluxDB
InfluxDB is an open source time series database designed to handle high write and query loads. It is designed to be used for use cases involving large amounts of time stamped data such as monitoring, IoT sensor data and real time analytics. A common use case for InfluxDB with Kubernetes is centralized aggregation of Prometheus metrics data from multiple clusters for long term storage etc.
What Will You Do¶
In this exercise,
- You will create a workload using InfluxDB's official Helm chart
- You will then deploy InfluxDB to a managed cluster (perhaps hosting shared infrastructure services used by applications deployed in the same or different clusters)
Important
This recipe describes the steps to create and use a InfluxDB workload using the Web Console. The entire workflow can also be fully automated and embedded into an automation pipeline.
Assumptions¶
- You have already provisioned or imported a Kubernetes cluster using the controller
- You have Helm CLI installed locally to download the InfluxDB helm chart
Challenges¶
Although deploying a simple Helm chart can be trivial for a quick sniff test, there are a number of considerations that have to be factored in for a stable deployment. Some of them are described below.
Ingress¶
The InfluxDB service deployed on the cluster needs to be exposed externally for it to be practical. In this recipe, we will use the managed nginx Ingress Controller in the default blueprint to expose the InfluxDB service externally.
Certificate Lifecycle¶
InfluxDB's Ingress needs to be secured using TLS. It is impractical to manually handle certificates and private keys. In this recipe, we will use a cert-manager addon in our cluster blueprint to manage the lifecycle of certificates for the InfluxDB Server's Ingress.
Secrets Management¶
It is imperative to secure InfluxDB's admin user" and "admin password" and not have users manually handle these secrets. In this recipe, we will also use the controller's Integration with HashiCorp Vault to secure InfluxDB's credentials.
Backup InfluxDB Data¶
It is important to regularly backup data for your InfluxDB using an object storage like AWS S3 so you can restore in case of a disaster.
Step 1: Download Helm chart¶
Use your helm client to download the latest release of InfluxDB helm chart file influxdb-x.y.z.tgz to your machine influxdb-helm-chart
- Add Influx Data's repo to your Helm CLI
helm repo add influxdata https://influxdata.github.io/helm-charts
- Now, fetch the latest Helm chart for InfluxDB from this repo.
helm fetch influxdata/influxdb
Note
In this recipe, we used influxdb-4.8.2.tgz of the InfluxDB Helm chart
Step 2: Customize Values¶
In this step, we will be creating a custom "values.yaml" file with overrides for our InfluxDB deployment.
- Copy the following yaml document into the "influxdb-custom-values.yaml" file
## influxdb custom values
## Specify a service type
## Change to NodePort or LoadBalancer if does not want to use ingress
##
service:
type: ClusterIP
## Persist data to a persistent volume
##
persistence:
enabled: true
# storageClass: "-"
accessMode: ReadWriteOnce
size: 8Gi
## Configure resource requests and limits
resources:
requests:
memory: 256Mi
cpu: 0.1
limits:
memory: 2Gi
cpu: 2
## Configure ingress for influxdb if you would like to expose the influxdb using ingress
ingress:
enabled: true
annotations:
kubernetes.io/ingress.class: nginx
cert-manager.io/cluster-issuer: "letsencrypt-http"
hostname: influxdb.eks.gorafay.net
path: /
tls: true
secretName: influxdb-ingress-tls
## Add pod annotations to use the vault intergation
podAnnotations:
rafay.dev/secretstore: vault
## replace "infra" with your configured vault role
vault.secretstore.rafay.dev/role: "infra"
## Add ENV for getting influxdb admin username and password from vault secret stores
env:
## replace infra-apps/data/influxdb#data.admin_username with the vault secret path to your influxdb admin username
- name: INFLUXDB_ADMIN_USER
value: secretstore:vault:infra-apps/data/influxdb#data.admin_username
## replace infra-apps/data/influxdb#data.admin_password with the vault secret path to your influxdb admin password
- name: INFLUXDB_ADMIN_PASSWORD
value: secretstore:vault:infra-apps/data/influxdb#data.admin_password
# Configure init script to create database
#
initScripts:
enabled: true
scripts:
init.iql: |+
CREATE DATABASE "prometheus" WITH DURATION 30d REPLICATION 1 NAME "rp_30d"
# Configure backup for influxdb if not yet have backup solution at cluster level
backup:
enabled: true
## By default emptyDir is used as a transitory volume before uploading to object store.
## As such, ensure that a sufficient ephemeral storage request is set to prevent node disk filling completely.
resources:
requests:
# memory: 512Mi
# cpu: 2
ephemeral-storage: "8Gi"
# limits:
# memory: 1Gi
# cpu: 4
# ephemeral-storage: "16Gi"
## If backup destination is PVC, or want to use intermediate PVC before uploading to object store.
persistence:
enabled: true
# storageClass: "-"
accessMode: ReadWriteOnce
size: 8Gi
## Backup cronjob schedule
schedule: "0 0 * * *"
## Amazon S3 or compatible
## Secret is expected to have AWS (or compatible) credentials stored in `credentials` field.
## for the credentials format.
## The bucket should already exist.
s3:
destination: s3://influxdb-bk/demo
## Optional. Specify if you're using an alternate S3 endpoint.
#endpointUrl: ""
Step 3: Create Workload¶
- Login into the Web Console and navigate to your Project as an Org Admin or Project Admin
- Under Infrastructure (or Applications if accessed with Project Admin role), select "Namespaces" and create a new namespace called "influxdb"
- Go to Applications > Workloads
- Select "New Workload" to create a new workload called "influxdb"
- Ensure that you select "Helm" for Package Type and select the namespace as "influxdb"
- Click CONTINUE to next step
- Upload the downloaded InfluxDB helm chart influxdb-x.y.z.tgz to the Helm > Choose File
- Upload the influxdb-custom-values.yaml created file from the previous step to Values.yaml > Choose File
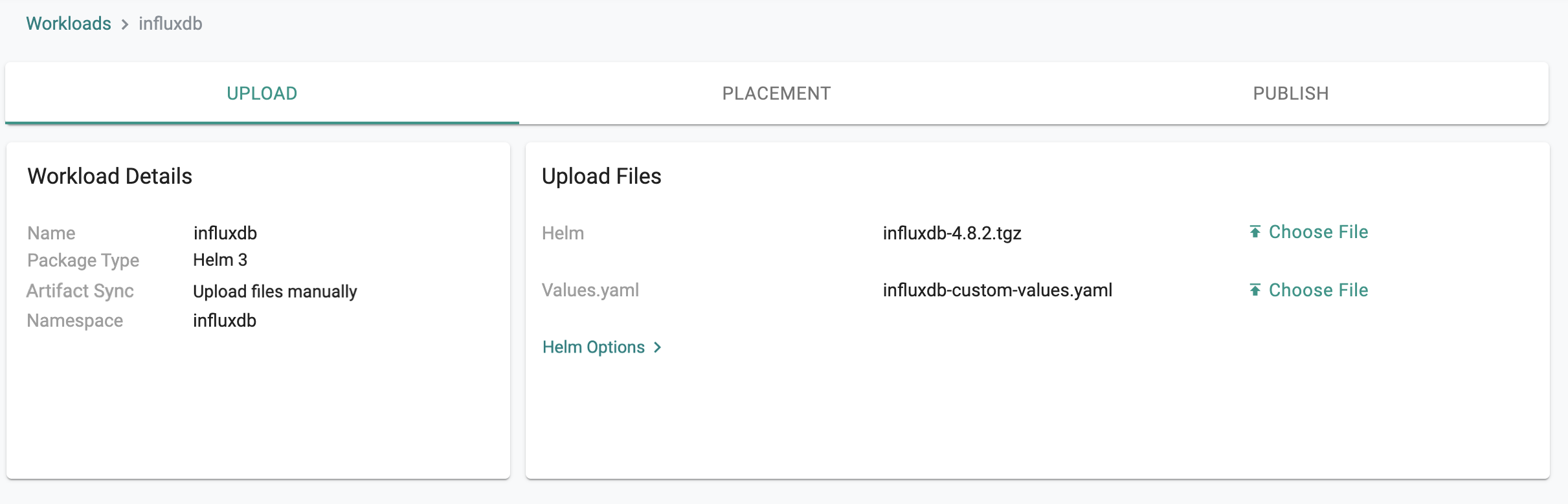
- Save and Go to Placement for the next step
- Select the cluster that you would like to deploy InfluxDB
- Publish the InfluxDB workload to the selected cluster
Step 4: Verify Deployment¶
You can optionally verify whether the correct resources have been created on the cluster.
- Once the workload is published, click on Debug
- Click on Kubectl to open a virtual terminal for kubectl proxy access right to the "influxdb" namespace context of the cluster
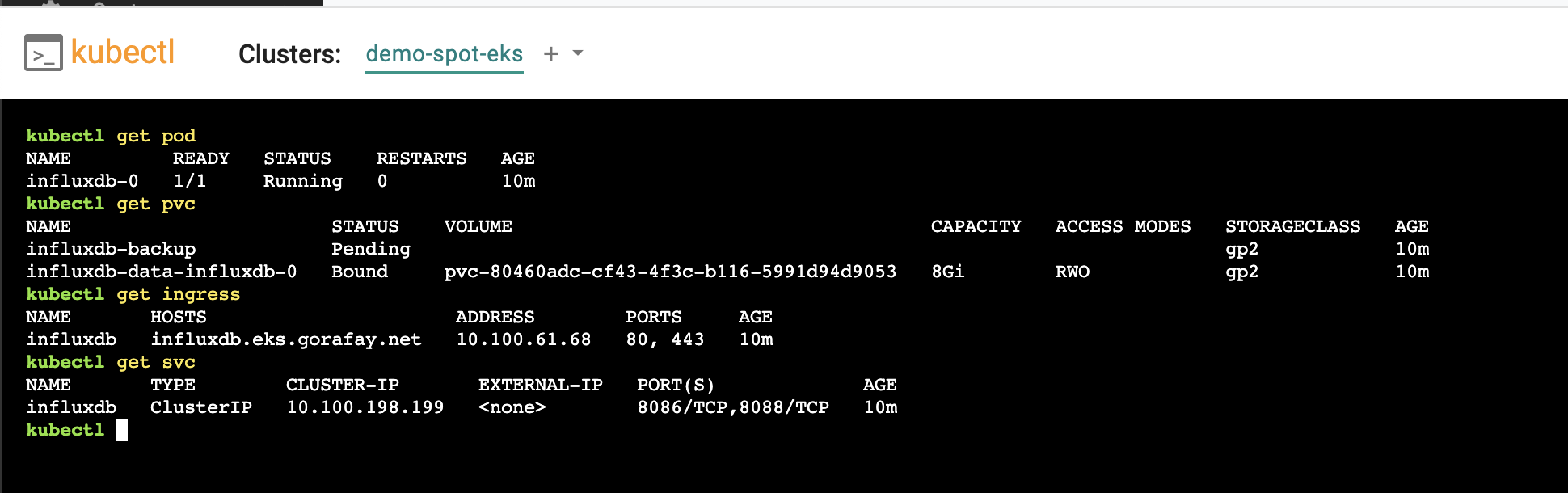
- First, we will verify the status of the pods
kubectl get pod
- Second, we will verify the InfluxDB persistent volume claim status
kubectl get pvc
- Next, we will verify the Ingress for InfluxDB service
kubectl get ingress
- Finally, we will verify the InfluxDB service
kubectl get svc
Shown below is an example for what you should see on a cluster where InfluxDB has been deployed as a Helm workload through the controller.
Alternatively, users with Infrastructure Admin or Organization Admin roles can view the status of all Kubernetes resources created by this InfluxDB workload by going to Infrastructure > Clusters > cluster_name > Resources and filter by Workloads "influxdb" as below:
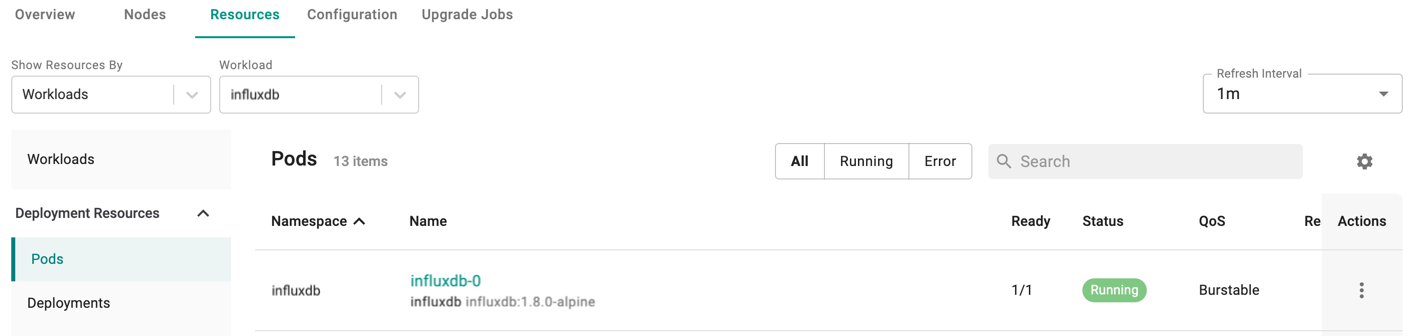
Step 5: Verify InfluxDB Backup Cronjob¶
- First, we will verify the InfluxDB backup cronjob is created
kubectl get cronjob
NAME SCHEDULE SUSPEND ACTIVE LAST SCHEDULE AGE
influxdb-backup 0 0 * * * False 0 30s 50m
- Second, once the job is scheduled, check the job status
kubectl get job
- Next, we will verify the InfluxDB backup pvc status
kubectl get pvc
- Next, we will check the InfluxDB backup pod status
kubectl get pod
- And finally, we will verify the logs of InfluxDB backup pod to ensure the backup data is uploaded successfully to S3 bucket
kubectl logs influxdb_backup_pod_name
- Shown below is an example for what you should see on a cluster where InfluxDB backup job has run.
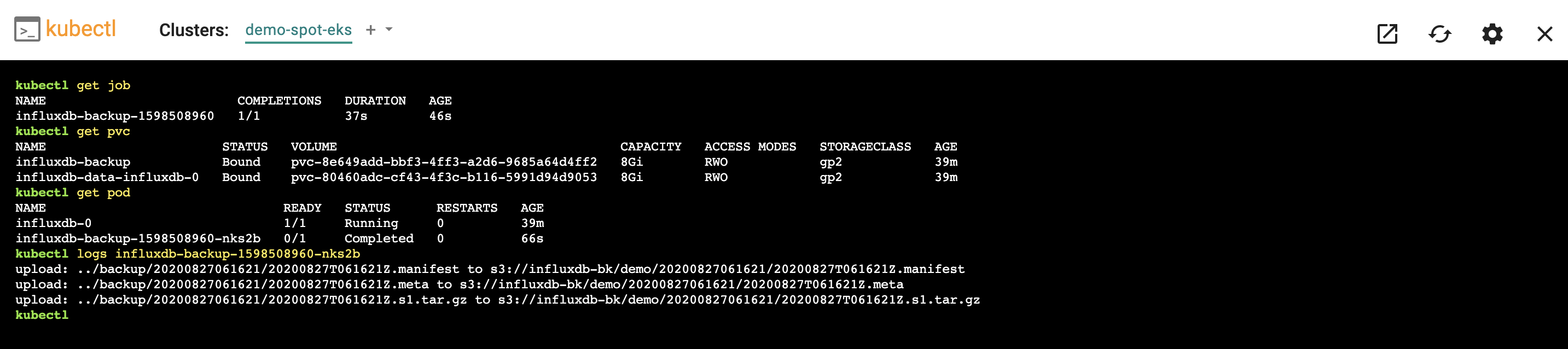
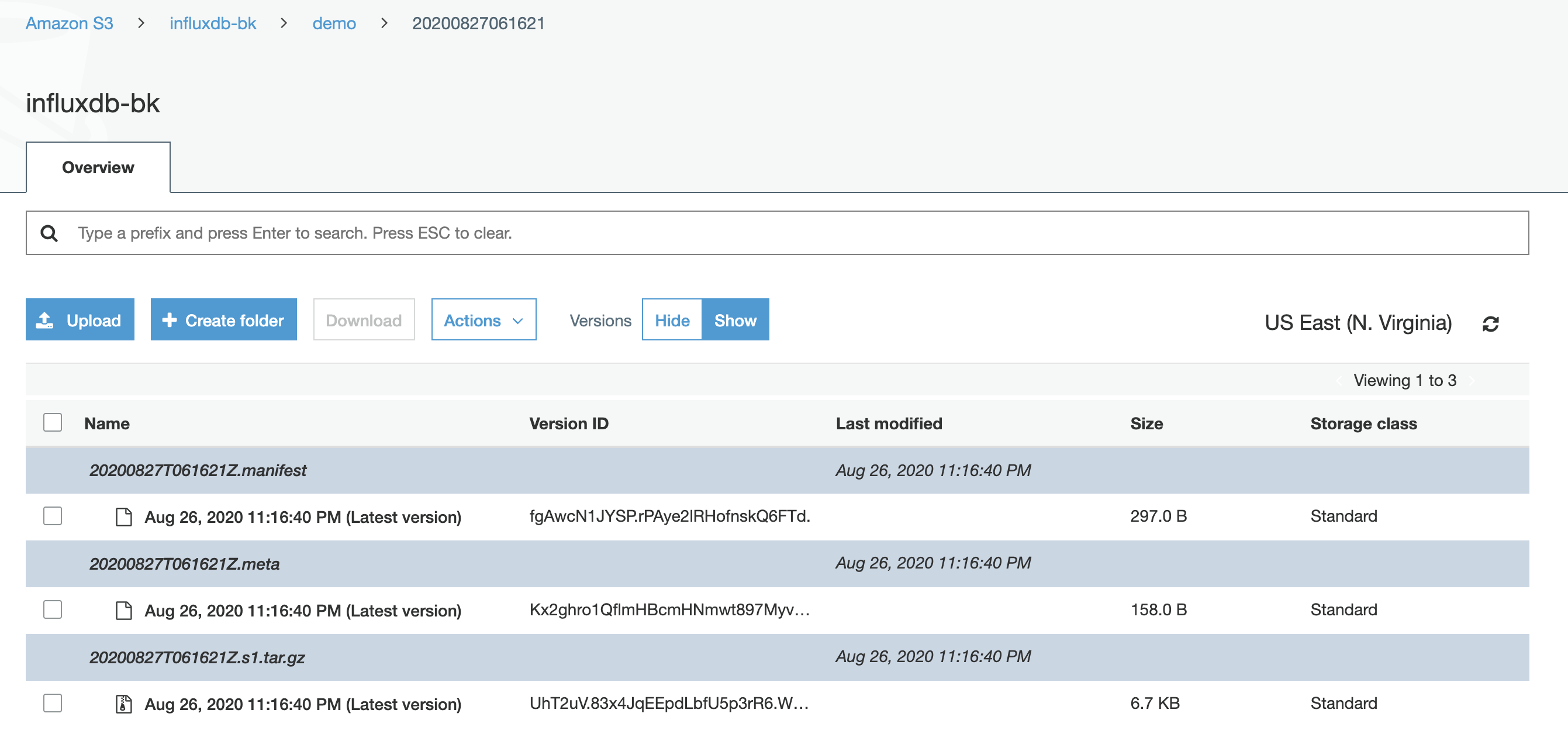
- Then, check the InfluxDB backup data is stored in S3 bucket
Recap¶
Congratulations! You have successfully deployed the InfluxDB time series database to a managed cluster.
You can now start using this InfluxDB time series database for your applications.
One example is to use InfluxDB to store Prometheus Metrics from Kubernetes Clusters with remote_write option.
More information on how to deploy Prometheus with the controller can be found at here