Health
Overview¶
At steady state, once a number of clusters have been successfully provisioned and operational, it is important for admins to monitor the "health" and "capacity" of the clusters.
The Controller provides a number of built in capabilities to assist users with this. The managed clusters maintain a near real time heart beat with the Controller. Unhealthy clusters will no longer be able to maintain a heart beat.
A cluster is deemed as "Healthy" (Green) if the answers to the following questions are TRUE
- Does the cluster have network connectivity to the Controller?
- Are critical infrastructure pods in monitored namespaces (privileged namespaces and kube-system) healthy and operational?
The cluster's "health" status is displayed on the Console. Operations teams are also presented with a "Last Check In" time that provides an indication of when the cluster was last seen by the Controller.
Once the cluster's health status change is detected by the Controller, it will automatically send out a notification to the Operations team via email so that they can react and respond if issues occur. The Web Console also presents deep diagnostic information that will help assess both the health of the cluster, critical services and customer workload pods.
A number of "Dashboards" are available on the Web Console which will help the administrator answer questions about the following:
- Cluster Health
- Node Health
- Pod Health
- Capacity and Utilization
Data Refresh Interval¶
By default, the information on the page will automatically refresh every "30 seconds". - Users can also temporarily update the default refresh interval from 30 seconds to 10 or 20 seconds if they require. - Users can click on the Refesh button if they would like to refresh the data immediately.
Reachability¶
The managed clusters maintain a continuous heartbeat with the controller. At steady state, for clusters with a confirmed heartbeat, the "reachability check" confirms this status.

If the controller loses the hearbeat with a managed cluster, the "reachability check" is shown appropriately.
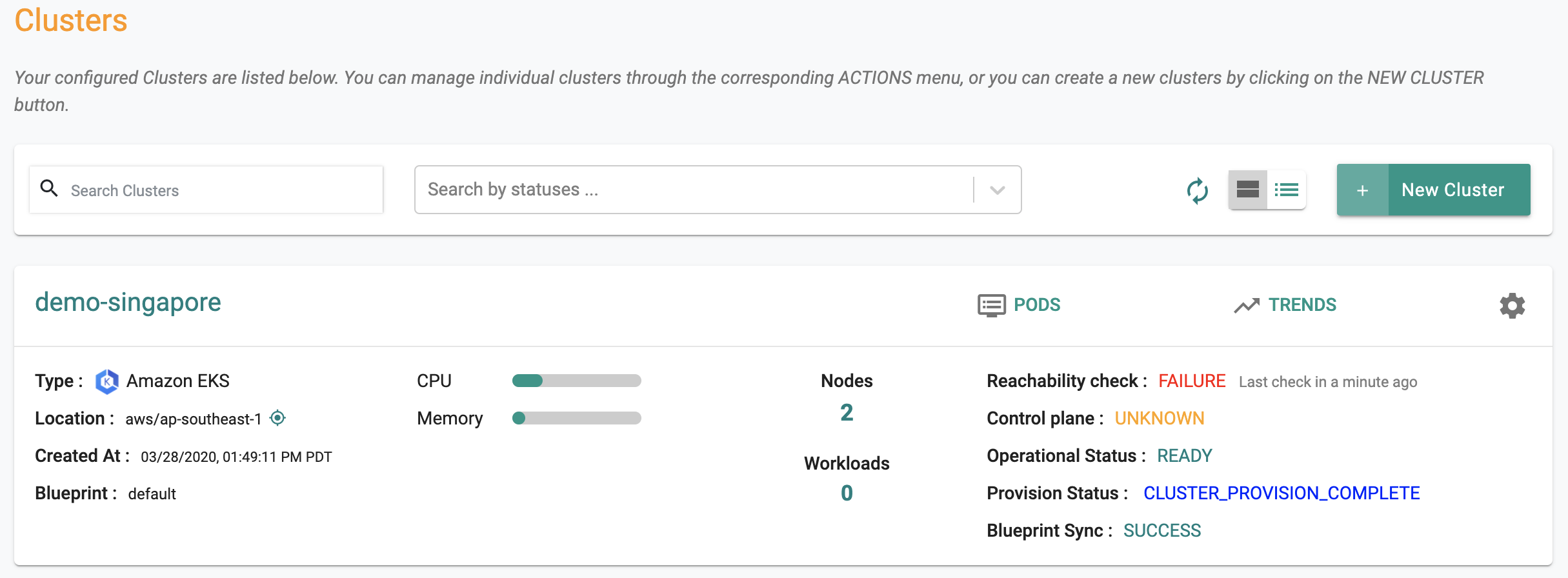
Control Plane Health¶
The control also actively monitors the health of the cluster's "control plane". This translates the health of the pods in three critical namespaces
- kube-system: Pods in core Kubernetes namespace
- rafay-system: Pods that are critical for connectivity to the controller
- rafay-infra: Pods for critical managed add-ons
Events, Alerts and Notifications¶
The controller operates a non-stop control loop constantly checking the status and health of the managed clusters and the workloads on them.
Events are generated and capture in case of a failure. Alerts are generated if the events do not resolve automatically. The controller can be configured to notify users if alerts are generated.