Restore Job
A restore job performs the action of restoring data on clusters in compliance with the configured restore policy. Follow the instructions here to create a restore policy.
Typical use cases for restore jobs from a backup snapshot are:
- Roll back to a good known configuration of specific application namespaces
- Migrate a cluster from one environment to another
- Restore the cluster to recover from disasters like hardware failure etc.
Configuration¶
Use the steps below to perform a restore job.
- From the web console, navigate to your Project
- Go to Backup/Restore -> Jobs
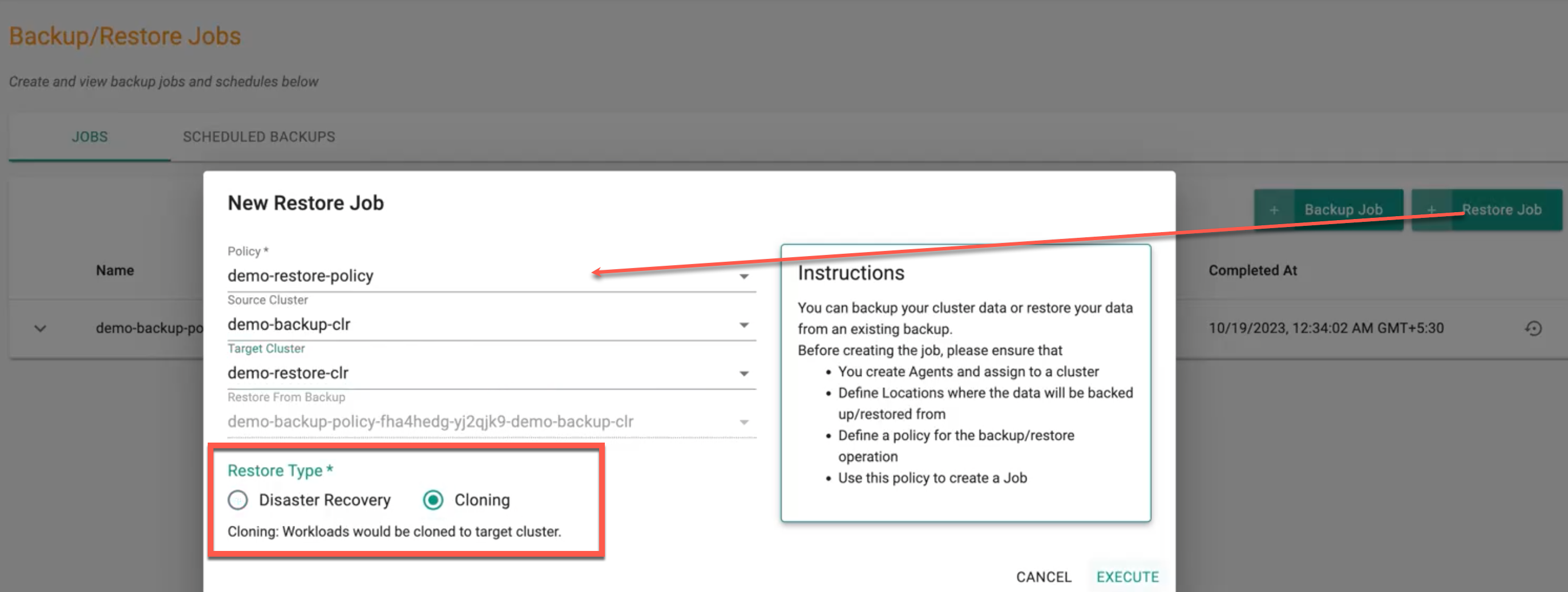
- Click on "Restore Job" to create a new restore job
- Select the Restore Policy from the "Policy" drop down list
- Select the source cluster name from the dropdown, from which you would like to restore
- Select a cluster from the dropdown which you would like to restore to
- Select the cluster's backup snapshot to "restore from" in the "Restore From Backup" drop down list.
- Specify the Resource Type: Either Disaster Recovery or Cloning. Opting for Disaster Recovery will migrate the workloads to the target cluster, removing it from the source cluster. while choosing "Cloning" will clone the workloads to the target cluster, leaving them present in both the source and target clusters.
- Click "EXECUTE" to perform the restore for your cluster from the selected backup snapshot with the configured restore policy.
Important
If the source and target clusters are identical, the Restore type options will not be available. By default, Disaster Recovery type is considered
- Once the restore job is complete, the restore job status will be displayed in the "JOBS" list
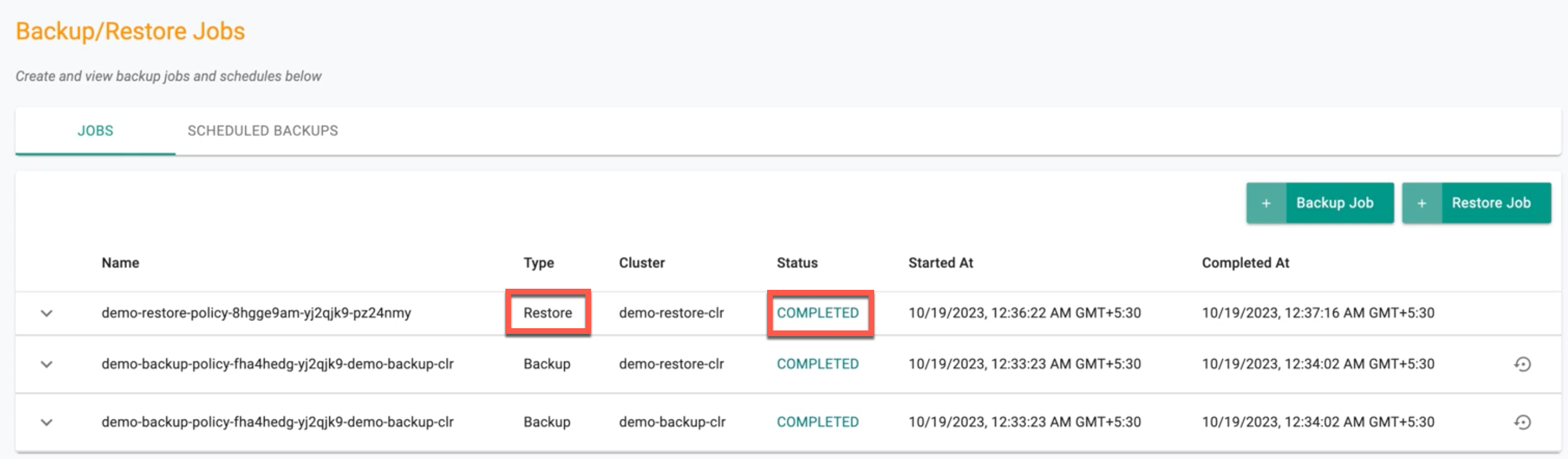
To learn more about a restore job, click the expand/collapse button
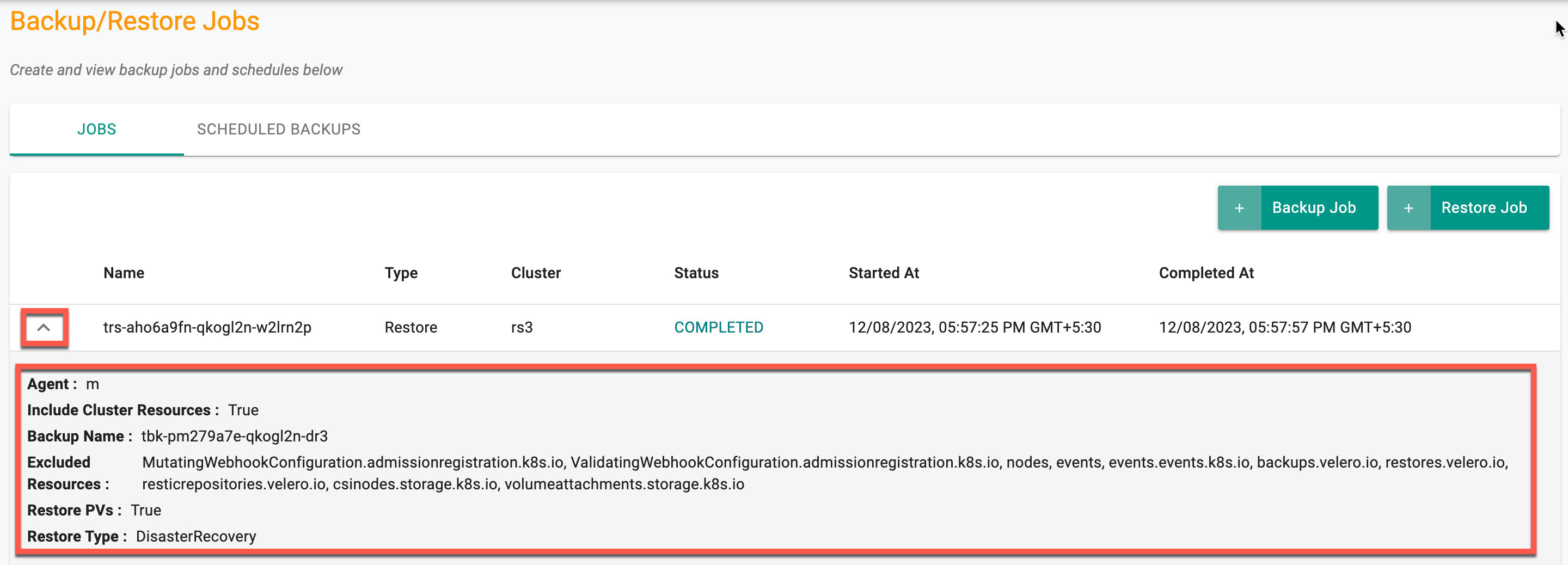
Optionally, you can also verify the restore results and logs in your AWS S3 bucket or S3 Compatible Storage. Here is an example of the restore results and logs of the cluster in a MinIO storage bucket.