CPUs and GPUs: What to use when for AI/ML workloads¶
This is a multi-series blog on GPUs, how they intersect with Kubernetes and containers. In this blog, we will discuss how CPUs and GPUs are architecturally similar and different. We will also review when it is ideal to use a CPU vs a GPU.

Background¶
Historically, the most important infrastructure decision for applications involved selecting from a combination of processors (CPU) and memory (RAM). The landscape has changed dramatically since then with GPUs becoming equally important for modern applications.
Graphics Processing Unit (aka GPUs) were originally designed to create images for computer graphics and video game consoles. The primary use case for a GPU has expanded significantly since then with applicability across all industries with applications such as high performance computing (HPC), rendering/animation, mapping etc.
However, it is also important to understand that a CPU cannot be fully replaced by a GPU. Rather, a GPU complements a CPU by allowing repetitive calculations to be run in parallel while the main application continues to run on the CPU. The CPU acts as the taskmaster coordinating a wide range of general-purpose computing tasks and the GPU performing a narrower range of extremely specialized tasks.
How is a GPU different from a CPU?¶
To understand how a GPU is different from a CPU, let us look at a typical server in a data center. This server might have 24-to-48 fast CPU cores. However, by adding just 4 to 8 GPUs to the same server will provide applications with access to ~40,000 additional cores. As you can see, the difference can be dramatic for applications.
Structurally, a GPU is extremely similar to a CPU. It comprises essentially the same components: DRAM, control unit, cache and an ALU. But, compared to a CPU, a GPU will have a significantly larger number of cores with less complicated control units and ALUs, and smaller caches.
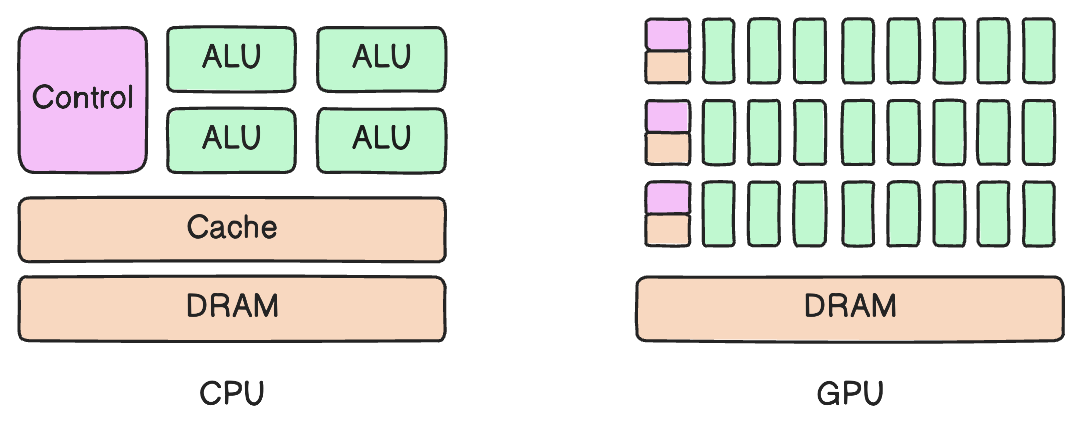
The main difference between a CPU and a GPU is how they process the instructions given to them. A CPU receives a set of instructions and processes it sequentially and in order. GPUs can spread/distribute the workload into parallel processes. So, while a CPU can theoretically complete any task, a GPU can complete simpler, more specific tasks extremely quickly and efficiently.
As a result, the most common use case for a GPU is for offloading of certain calculations from the CPU. The table below captures the high level differences between a CPU and a GPU.
| CPU | GPU |
|---|---|
| Generalized i.e. can handle all processing functions | Specialized i.e. can handle specific types of tasks extremely well |
| Has fewer cores (low 100s at max), but very fast cores | Has 1,000s of slower cores, packaged densely on the chip |
| Processes instructions serially | Processes instructions in parallel |
| Low latency | High throughput |
| Well suited for use cases where interactivity is critical | Well suited for batch operations |
Summary¶
One of the design principles of a GPU is that all the kernels can only process the same operation at the same time i.e. SIMD aka "sim-dee". For a use case such as trying to crack a password hash, the GPU would divide each instruction into separate threads that it can compute in parallel.
For use cases such as model training, it is common for users to pursue a hybrid (CPU + GPU) approach. Intelligent use of both CPUs and GPUs will ensure that users have an effective (cost + time) solution. While GPUs are extremely well suited to train large deep learning models, CPUs are extremely well suited for data preparation and feature extraction stages. In fact, CPUs can also be used effectively for small-scale models. For inference and hyperparameter tuning, both CPUs and GPUs can be utilized. By understanding the differences between a CPU and GPU, users can make informed decisions about which hardware to use for their specific needs.
For example,
Data Preprocessing
It can be extremely cost effective to use a CPU to perform data preprocessing tasks such as image resizing and feature extraction and use a GPU to perform forward propagation.
Model Initialization
It can be efficient to use a CPU to initialize the weights and biases of the model and then transition to a GPU to train the model.
Transfer Learning
Train a small neural network on a CPU to extract features from an image, then use a GPU to train a larger neural network for image classification.
What Next?¶
Rafay's AI Suite addresses a number of key challenges for organizations that are actively pursuing use cases in HPC or traditional ML or Generative AI powered by LLMs. In the upcoming blogs, we will look at the following topics:
- Why are containers used pervasively for AI/ML?
- How do GPUs work in Kubernetes?
- What are the limitations with GPUs on Kubernetes that users need to take into consideration and how they can be overcome? etc.
Sincere thanks to readers of our blog who spend time reading our product blogs. This blog was authored because we have been working closely with a number of customers that are actively working on AI/ML use cases on Kubernetes enabled with GPUs. Please Contact the Rafay Product Team if you would like us to write about other topics.