This is in continuation of our first blog where we introduced Flatcar Linux. In part 2, we will show how you can install a Flatcar Container Linux instance locally on your laptop so that you can learn more about it. This guide will take you through the steps to install it, boot the instance, SSH into it. Finally, we will explore and validate some of Flatcar's critical features that we reviewed in the first blog.
Follow the steps below to download, set up, and run a Flatcar instance locally. In our example, we are installing this on a M1 MacBook Pro.
First, install QEMU on your system. Follow the instructions provided here.
Get the QEMU helper script and the latest stable Flatcar image
wget https://stable.release.flatcar-linux.net/amd64-usr/current/flatcar_production_qemu.sh
wget https://stable.release.flatcar-linux.net/amd64-usr/current/flatcar_production_qemu_image.img.bz2
Decompress the downloaded image
bzip2 --decompress --keep flatcar_production_qemu_image.img.bz2
Set execution permissions for the QEMU helper script:
chmod +x flatcar_production_qemu.sh
Use the following command to start the Flatcar instance with 4 CPUs and 4GB memory in console mode:
./flatcar_production_qemu.sh -M 4096 -- -smp 4 -display curses
Once the Flatcar instance is running, set up your SSH configuration to connect to it. Update your SSH config file as follows:
# ~/.ssh/config
Host flatcar
User core
StrictHostKeyChecking no
UserKnownHostsFile /dev/null
HostName 127.0.0.1
Port 2222
You can then SSH into the instance using the following command
After you successfully SSH into the instance, you can run the following command to verify the system's firmware and kernel details:
You should see something like the image below.
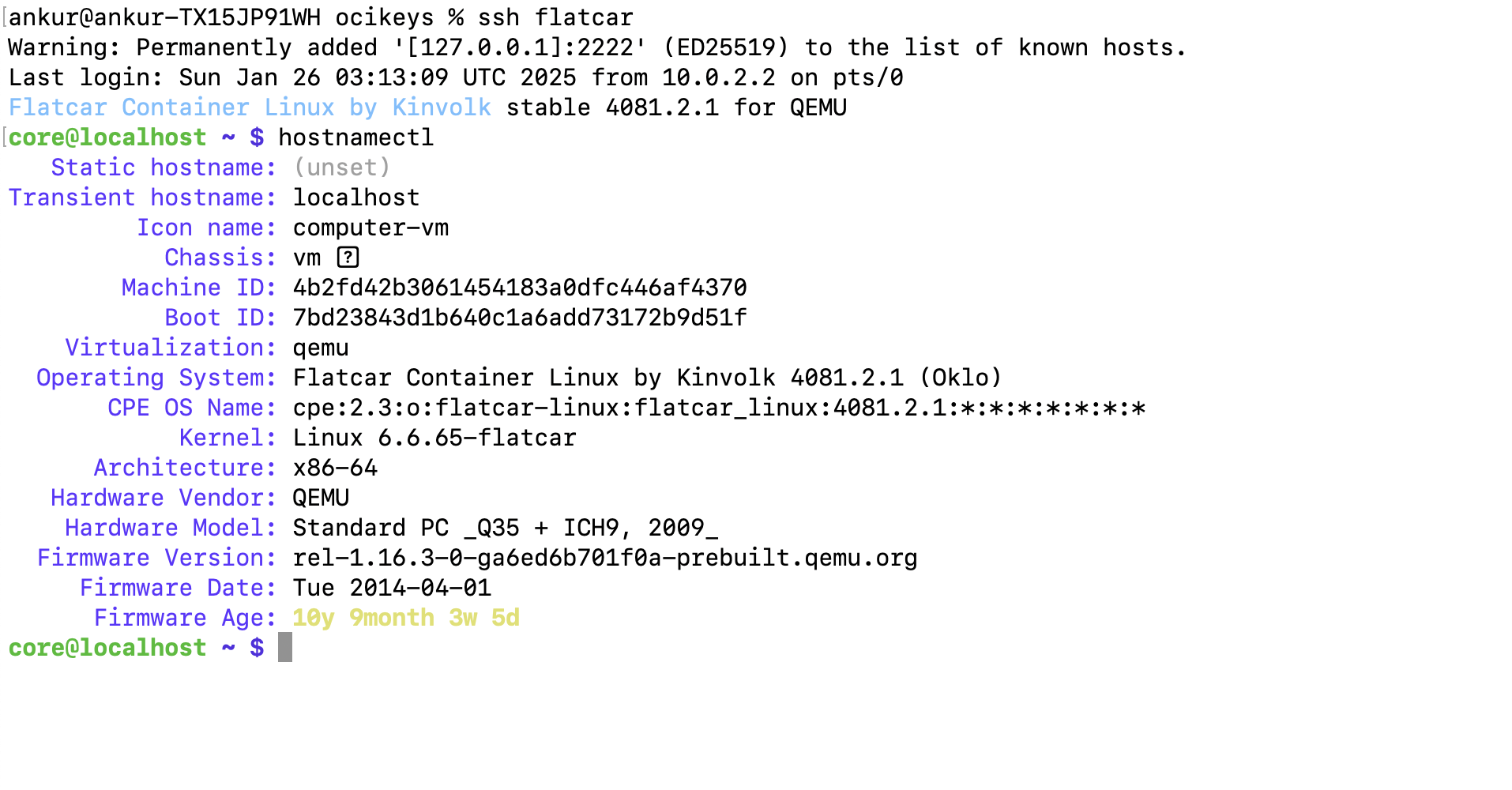
In the image above, notice that the Flatcar version is 4081.2.1. Here’s how the versioning system works for Flatcar Linux.
- 4081: The number of days since the first CoreOS release. (Flatcar is a fork of CoreOS)
-
2: Minor number representing the promotion level:
- 0 = Alpha
- 1 = Beta
- 2 = Stable
- 3 = LTS
-
1: Patch level, indicating small updates like kernel or software fixes.
In our version (4081.2.1), 2 represents a stable release on its first patch.
Now that we have installed Flatcar Linux, let us test and validate some of the interesting features of Flatcar.
In Linux, the /usr directory is used to store user system resources. It contains the majority of the system’s software and programs i.e. binaries, libraries, documentation, and other files shared by all users of the system. Flatcar Linux makes the /usr directory read-only as part of its design philosophy to ensure system immutability and reliability. By focusing on immutability and containerization, Flatcar Linux achieves a stable, predictable, and secure platform, which is why /usr is deliberately set to read-only.
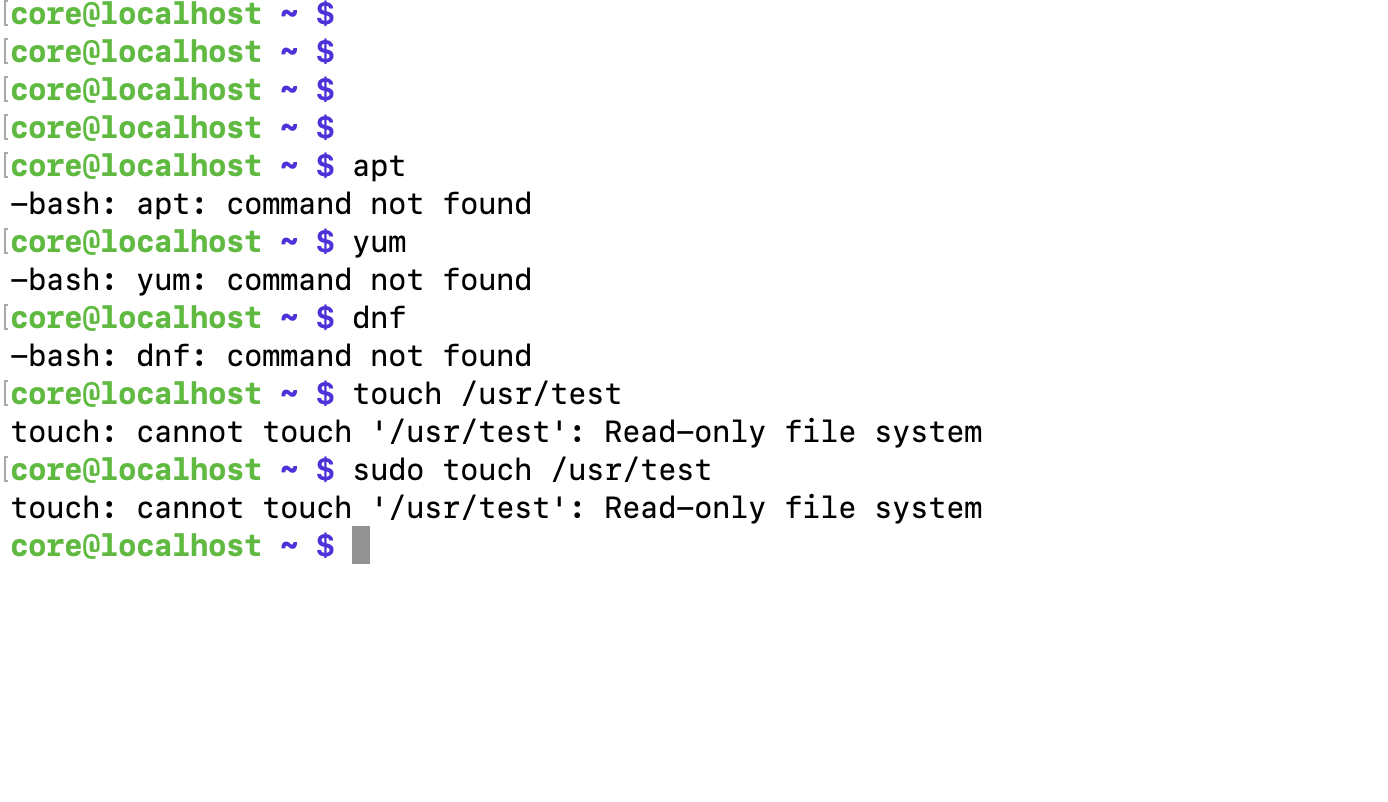
Let's test whether Flatcar Linux's /usr folder is immutable
- SSH into your Flatcar instance
- Run commands like
apt, yum, or dnf
You will notice they are unavailable. Additionally, any attempt to write to the /usr/ directory to see that the file system is immutable. For example, let's try to create a new file in the /usr directory using the "touch" command.
Below is an example screenshot showing this behavior:
Flatcar includes a auto update system by default. By default, the Flatcar instance will check for updates every hour, download them if available, and automatically reboot to apply updates to ensure that your instance is always current and up to date. Organizations can always self host their own update server ensuring that they can control how/when their Flatcar instances are kept current.
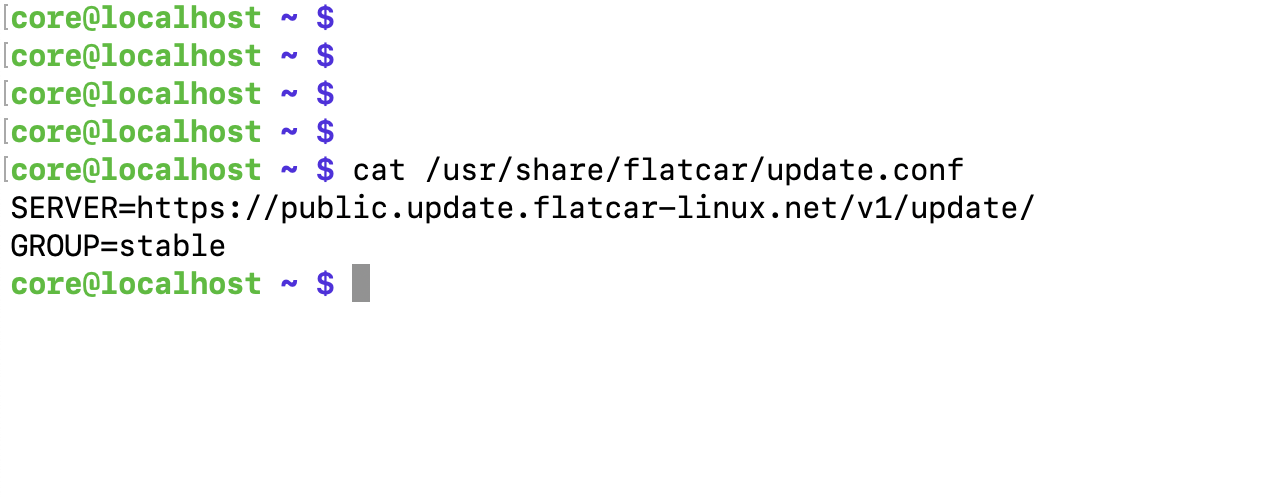
To view the update configuration, run the following command inside the Flatcar instance:
cat /usr/share/flatcar/update.conf
The output will look like this:
SERVER=https://public.update.flatcar-linux.net/v1/update/
GROUP=stable
- SERVER: This is the update server Flatcar uses to check for new releases.
- GROUP: Refers to the promotion level (e.g., stable).
Info
Administrators can customize the default behavior by configuring the upgrade strategy. For example, a common configuration is for administrators to specify a "maintenance windows" for reboots.
If you’re not using QEMU, you can install Flatcar Container Linux on other platforms like VirtualBox, Vagrant, and others. You can find detailed installation instructions for these platforms here. Flatcar also provides prebuilt images for cloud providers like AWS, Azure, Google Cloud, and others. These cloud platforms offer Flatcar-based AMIs or images to streamline deployment. Check out the cloud-specific installation steps here.
In this blog, we:
- Walked through the steps to install and run a Flatcar Container Linux instance locally.
- Validated some unique characteristics of Flatcar, such as its lack of a package manager and its auto-update system.
- Explored Flatcar versioning.
In the upcoming Part 3 of the blog series on Flatcar Linux, we will cover how to install Rafay's Kubernetes Distribution (Rafay MKS) on Flatcar and manage it centrally using the Rafay Platform.

 Live Demo
Live Demo