As Large Language Models (LLMs) like LLaMA, Mistral, and DeepSeek continue to scale into the hundreds of billions of parameters, model efficiency becomes as important as model quality.
One often-overlooked bottleneck is the model loading format. This is one of the primary focus areas for safetensors.
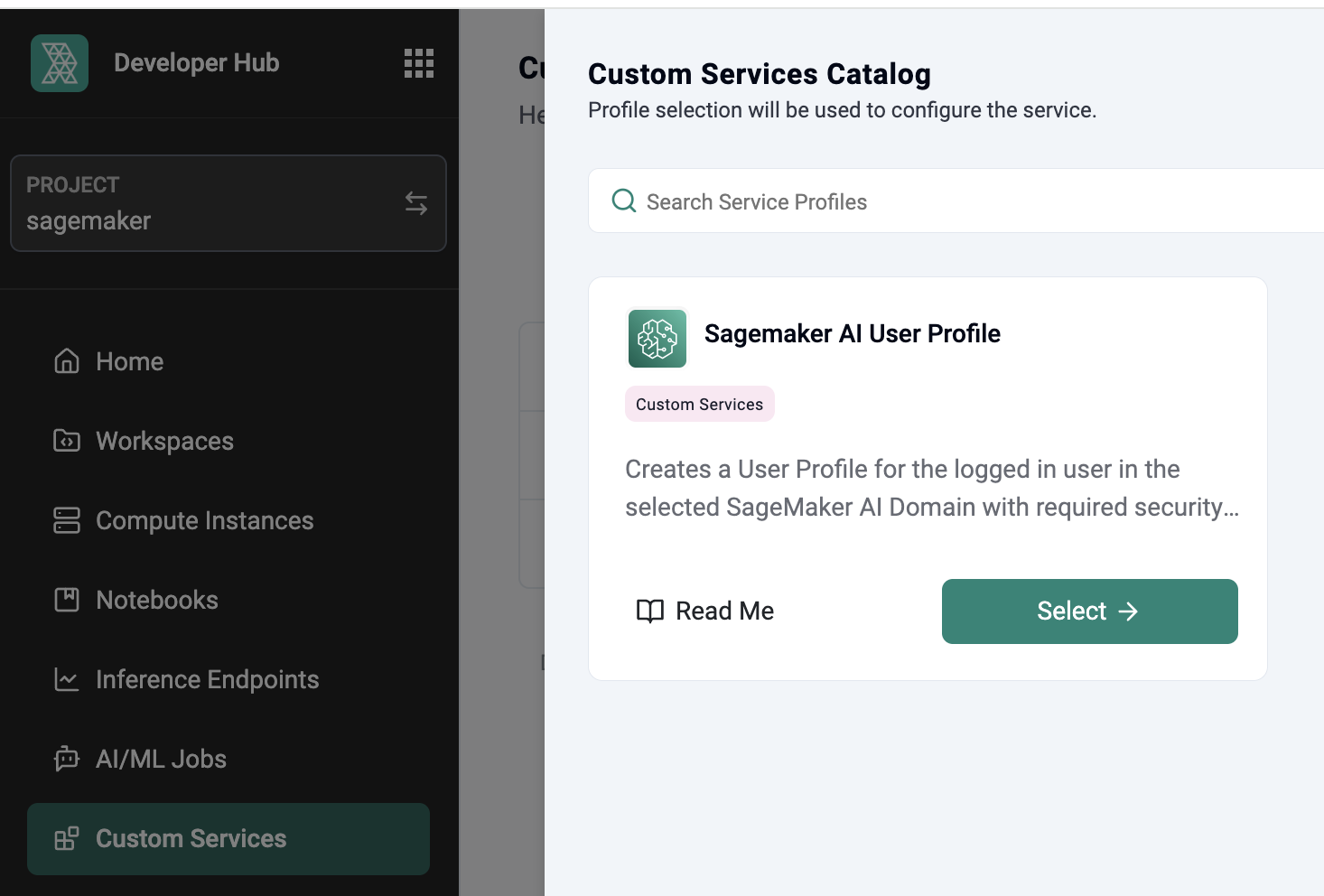
As organizations expand their use of Amazon SageMaker to empower data scientists and machine learning (ML) engineers, managing access to development environments becomes a critical concern. In the last blog, we discussed how SageMaker Domains can provide isolated, secure, and fully-featured environments for users.
However, manually creating user profiles for every user quickly becomes a bottleneck—especially in large or fast-growing organizations. Asking users to submit an IT ticket and wait for days before it can be fulfilled is unacceptable in today's fast paced environment.
In this blog, we will describe how organizations use Rafay's GPU PaaS to provide their users with a self-service experience to onboard themselves into SageMaker Domains without waiting on IT or platform teams. This not only improves efficiency and user experience but also ensures consistency and compliance across the organization.
As organizations continue to invest in artificial intelligence (AI) and machine learning (ML) to drive digital transformation, the demand for streamlined, secure, and scalable development environments has never been greater.
Many organizations that are standardized on Amazon AWS may use Amazon SageMaker AI to build, train, and deploy machine learning models at scale with minimal operational overhead. SageMaker AI provides a fully managed environment that streamlines the entire ML lifecycle, enabling faster innovation, stronger governance, and cost-effective AI development.
In this introductory blog, we will describe one of the most critical capabilities of SageMaker AI called Domains. In the next blog, we will describe how organizations can scale their AI/ML teams by providing their data scientists and ML engineers with a self service experience for access to SageMaker Domains.
This is part-1 in a blog series on Slurm. In the first part, we will provide some introductory concepts about Slurm. We are not talking about the fictional soft drink in the world of Futurama. Instead, this blog is about Slurm (Simple Linux Utility for Resource Management), an open-source, fault-tolerant, and highly scalable cluster management job scheduler and resource manager used in high-performance computing (HPC) environments.
Slurm was originally conceptualized in 2002 at Lawrence Livermore National Laboratory (LLNL) and has been actively developed and maintained especially by SchedMD. In this time, Slurm has become the defacto workload manager for HPC with >50% of the Top-500 super computers using it.
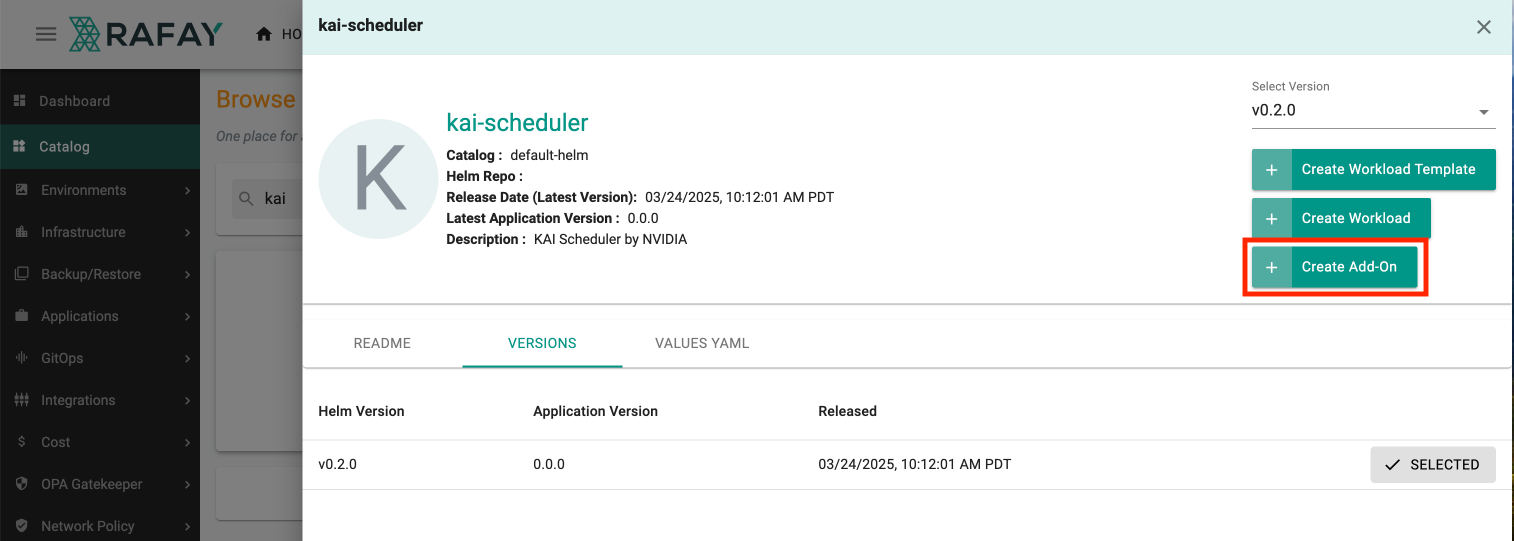
At KubeCon Europe, in April 2025, Nvidia announced and launched the Kubernetes AI (KAI) Scheduler. This is an Open Source project maintained by Nvidia.
The KAI Scheduler is an advanced Kubernetes scheduler that allows administrators of Kubernetes clusters to dynamically allocate GPU resources to workloads. Users of the Rafay Platform can immediately leverage the KAI scheduler via the integrated Catalog.
To help you understand the basics quickly, we have also created a brief video introducing the concepts and a live demonstration showcasing how you can allocate fractional GPU resources to workloads.
Deploying and operating an open-source Large Language Model (LLM) requires careful planning when selecting the right GPU model and memory capacity. Choosing the optimal configuration is crucial for performance, cost efficiency, and scalability. However, this process comes with several challenges.
In this blog, we will describe the factors that you need to consider to select the optimal GPU model for your LLM. We have also published a table capturing optimal GPU models to deploy and use Top-10 open source LLMs.
A few weeks back, Tiago Reichert from AWS published a very interesting blog on AWS Community showcasing how you can deploy and use the DeepSeek-R1 LLM on an Amazon EKS Cluster operating in Auto Mode. Detailed step-by-step instructions for this are documented in this Git Repo.
In this blog, we will describe how we took AWS's excellent blog and packaged it to provide a turnkey, 1-click self-service experience for non AWS administrator type users in a typical enterprise. It took one of our solution architects 30 minutes to wrap AWS's example code using Rafay's Environment Manager and PaaS.
Over the last few weeks, we have been asked to demonstrate this every day to several customers and partners. Given the significant interest in DeepSeek and the self service experience, we believe others will benefit from this blog.
In our first blog about Hubble for Cilium, we reviewed a real life example highlighting where traditional monitoring tools fall short. We then looked at how Hubble + Cilium can address these gaps. In the second blog, we discussed how Rafay provides our customers with a a tight, turnkey integration with Cilium for various cluster types (i.e. Rafay MKS for Data Centers and Public Cloud Distributions such as Amazon EKS).
In this get started guide, we will review how a platform engineer can configure, deploy and use Hubble for Cilium on a Rafay MKS Kubernetes cluster operating in a data center (aka on-premises environment). The three high level steps are:
Provision an Upstream Kubernetes Cluster in your data center using Rafay MKS
Configure and Deploy Cilium CNI as a software add-on in a Cluster Blueprint (i.e. Bring Your Own CNI)
In the first blog, we discussed how organizations can use Hubble for Cilium for observability. In this blog, we will look at how the Rafay Platform provides a tight, turnkey integration with Cilium making life easy for platform teams. In the next blog, my colleague will describe and showcase how an administrator can configure and enable Hubble on a Rafay MKS based Kubernetes cluster with the Cilium CNI.
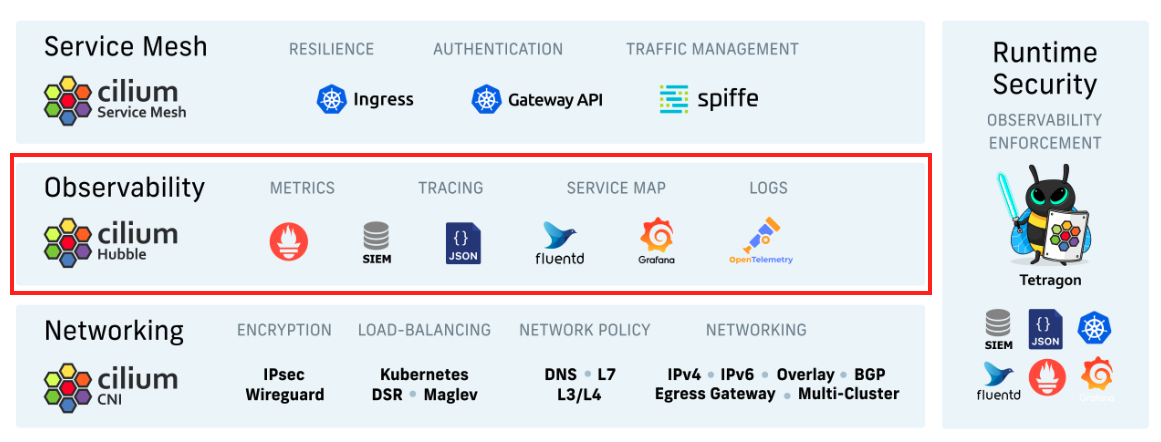
Networking observability in Kubernetes environments is essential for troubleshooting, security, and performance optimization. Hubble, an observability platform for the Cilium CNI, addresses this challenge by providing real-time insights into network traffic, security policies, and application-layer interactions. Hubble is built on eBPF (Extended Berkeley Packet Filter) and provides deep visibility into packet flows, service-to-service communication, and security enforcement without requiring intrusive packet mirroring or modifications to application code. In a nutshell, Hubble is a fully distributed networking and security observability platform for cloud native workloads.
In this introductory blog about Hubble for Cilium, We will start with a real life example highlighting where traditional monitoring tools fall short. We will then look at how Hubble + Cilium can address these gaps. In the second blog, I will describe how Rafay provides our customers with a a tight, turnkey integration with Cilium for various cluster types (i.e. Rafay MKS for Data Centers and Public Cloud Distributions such as Amazon EKS).