Our upcoming release introduces support for a number of new features and enhancements. One such enhancement is the introduction of Platform Versioning for Rafay MKS clusters a major feature in our v3.5 release. This new capability is designed to simplify and standardize the upgrade lifecycle of critical components in upstream Kubernetes clusters managed by Rafay MKS.
Upgrading Kubernetes clusters is essential, but the core components—such as etcd, CRI, and Salt Minion also require updates for:
- Security patches
- Compatibility with new Kubernetes features
- Performance improvements
Platform Versioning introduces a structured, reliable, and repeatable upgrade path for these foundational components, reducing risk and operational overhead.
A Platform Version defines a tested and validated set of component versions that can be safely upgraded together. This ensures compatibility and stability across your clusters.
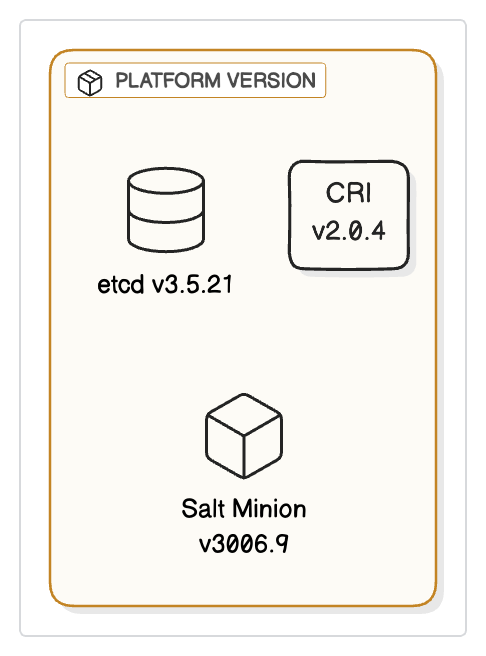
We are introducing v1.0.0 as the very first Platform Version for new clusters. This version includes:
- CRI: v2.0.4
- etcd: v3.5.21
- Salt Minion: v3006.9
Note
For existing clusters, the initial platform version will be shown as v0.1.0, which is assigned for reference purposes to older clusters that were created before platform versioning was introduced. Please perform the upgrade to v1.0.0 during scheduled downtime, as it involves updates to core components such as etcd and CRI.
You can upgrade the Platform Version in two ways:
- During a Kubernetes version upgrade
- As a standalone platform upgrade
This flexibility allows you to keep your clusters secure and up to date, regardless of your Kubernetes upgrade schedule.
Platform Versions are not released frequently. New versions are published only when:
- A high severity CVE or vulnerability is addressed
- A major performance or compatibility feature is introduced
- There are significant version changes in core components
This approach ensures that upgrades are meaningful and necessary, minimizing disruption.
Whenever a new Platform Version is released, existing clusters can seamlessly upgrade to the latest version, ensuring they benefit from the latest security patches and improvements without manual intervention.
We are committed to continuously improving Platform Versioning. In future releases, we will introduce new platform versions to to expand the scope of Platform Versioning by including more critical components as part of the platform version. For this initial release, we have started with three foundational components etcd, CRI, and Salt Minion because of their critical importance to cluster stability. Over time, we will enhance Platform Versioning to cover additional components, ensuring your clusters remain robust, secure, and up to date.
For detailed documentation, see: Platform Version Docs
Platform Versioning makes it easier than ever to keep your clusters current and secure by managing the upgrade lifecycle of foundational components like etcd, CRI, and Salt Minion.
Whether you apply it alongside a Kubernetes version bump or independently, Platform Versioning ensures your infrastructure remains stable, secure, and optimized now and in the future.