Solutions for Key Kubernetes Challenges for AI/ML in the Enterprise - Part 2¶
This is part-2 of our blog series on challenges and solutions for AI/ML in the enterprise. This blog is based on our learnings over the last two years as we worked very closely with our customers that make extensive use of Kubernetes for AI/ML use cases. In part-1, we looked at the following:
- Why Kubernetes is particularly compelling for AI/ML.
- Described some of the key challenges that organizations will encounter with AI/ML and Kubernetes
In this part, we will look at some innovative approaches by which organizations can address these challenges.
Issue 1: Infra Setup and Maintenance Complexity¶
One of the biggest challenges organizations encounter is with the complexity of infrastructure setup and maintenance for their AI/ML systems.
How can organizations abstract infrastructure complexity away from data scientists and deliver this to them "on demand" via a "self service" experience?
Self Service¶
Our customers in the public cloud templatize cluster provisioning using Rafay Environment Manager bootstrapped with cluster blueprints to provide their users a self service experience. Platform teams create validated cluster templates with the entire infrastructure stack (i.e. fully functional Kubernetes clusters preloaded with all the required software for AI/ML.)
Data scientists can then use these pre-validated cluster templates to provision their environments on demand.
flowchart LR
ds[Data Scientists]
plat[Platform Team]
subgraph rafay[Rafay]
direction TB
template[Cluster Template for AI/ML]
clusterA[Cluster 1]
clusterB[Cluster 2]
clusterC[Cluster 3]
template-.->clusterA
template-.->clusterB
template-.->clusterC
end
plat --Create--> template
ds --Use--> templateIn a nutshell, with Rafay, data scientists..
- Do not require expertise with features/services in the cloud
- Do not require expertise in IaC such as terraform or GitOps
- Do not require any form of "privileged access" to cloud infrastructure to provision using the templates
- Do not need to wait for days or weeks for ephemeral infrastructure to do their job
Using pre-validated cluster templates, data scientists can literally provision complete Kubernetes based operating environments for AI/ML based on Kubernetes with a click of a button.
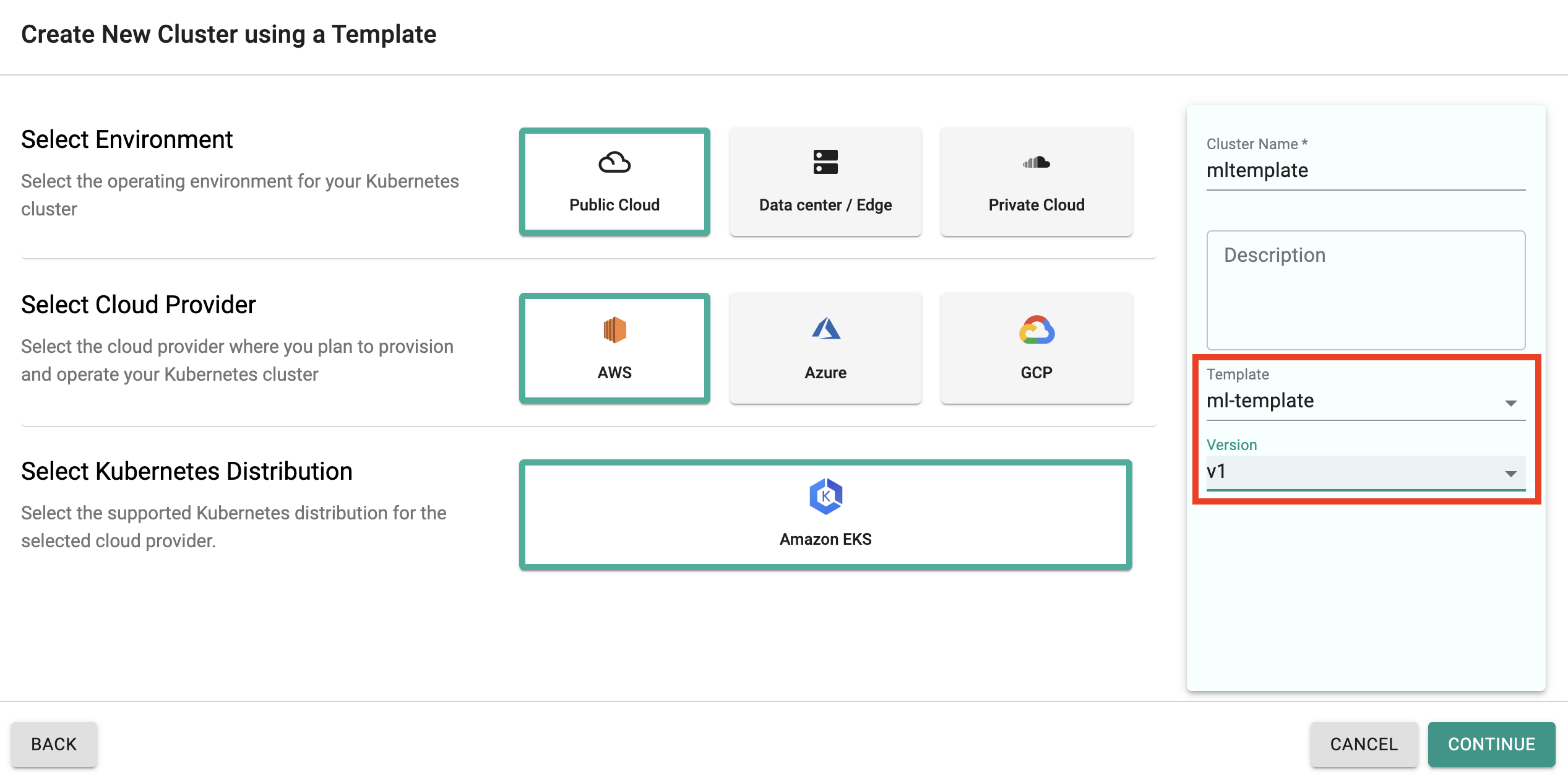
App Catalog¶
It is not scalable or practical to assume that data scientists will become expert Kubernetes users. They primarily only want to deploy and use their ML apps.
How can organizations provide data scientists a zero burden way to deploy and use ML apps on remote Kubernetes clusters?
Our customers use custom app catalogs to curate pre-validated applications. With this, the data scientists can just click to deploy and use complex ML apps on Kubernetes clusters.
Shown below is a screenshot showing what the creation of a custom app catalog looks like for a platform engineer.
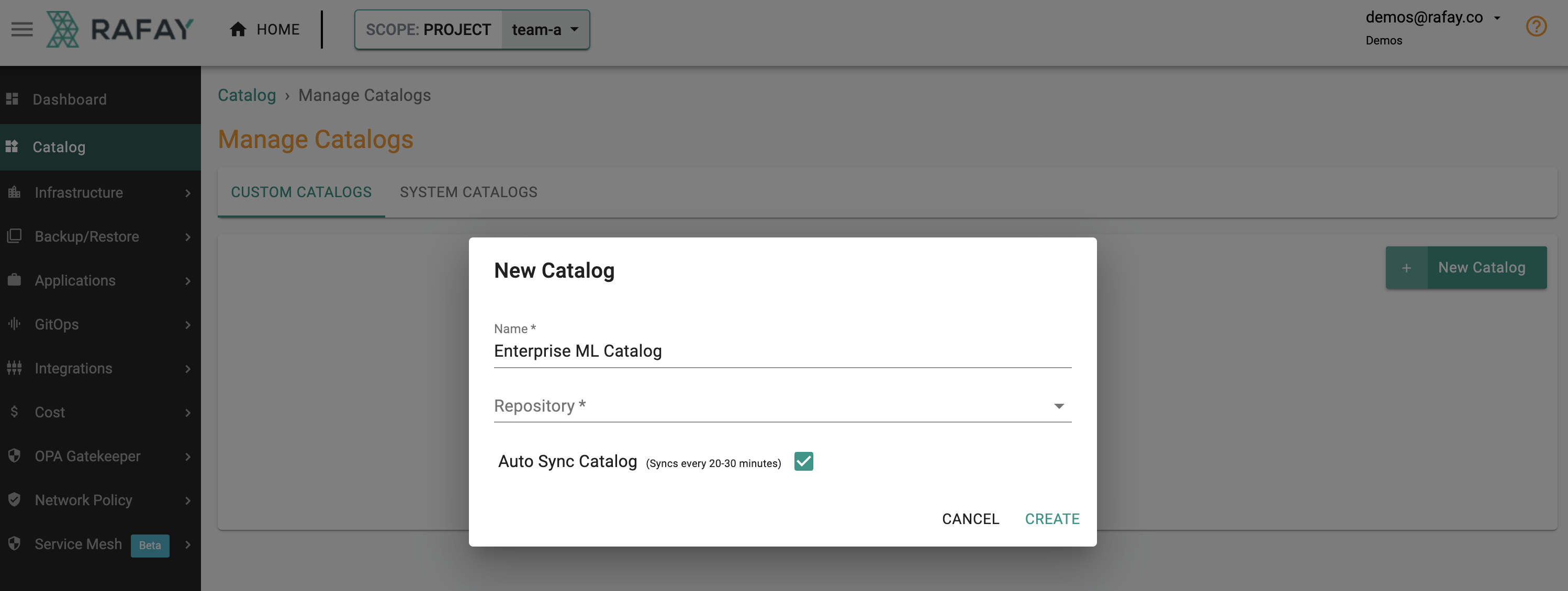
In a nutshell, with Rafay, data scientists do not require
- Expertise with kubectl and helm commands
- Expertise in how to troubleshoot Kubernetes applications
Shown below is a example of the experience for a data scientist deploying an AI/ML application from the custom catalog.
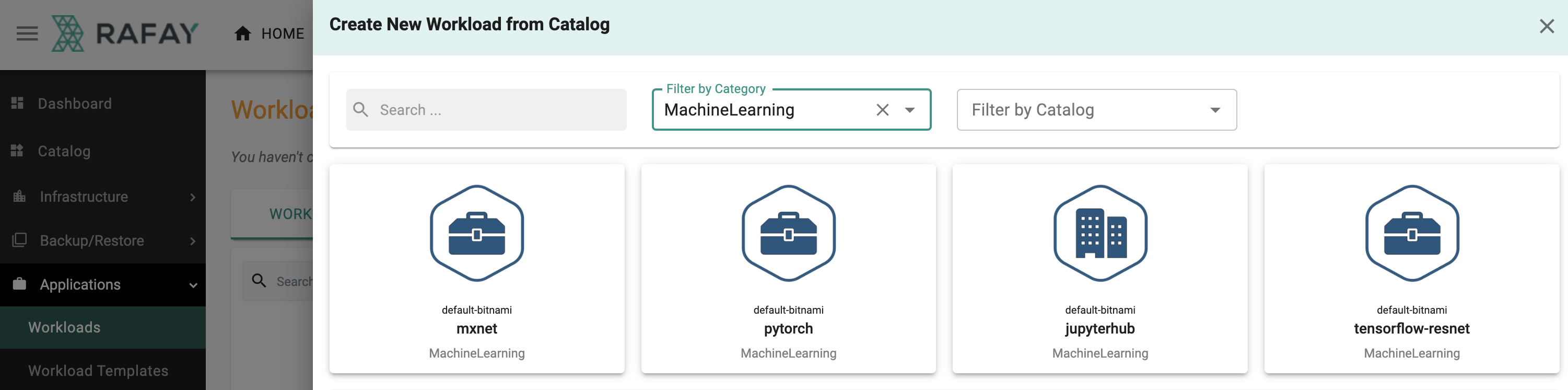
Issue 2: Security & Governance¶
As AI/ML goes mainstream supporting the primary revenue stream for organizations, these teams find themselves having to demonstrate that they are operating with world class security and governance.
How can organizations provide data scientists a standardized and well governed operations platform with an end-to-end audit trail?
Standardization¶
We see our customers using cluster blueprints as a way to create and manage version controlled organization wide standards for software add-ons to be deployed on their clusters.
flowchart LR
v1[Blueprint v1]-->v2[Blueprint v2]-->v3[Blueprint v3]Multitenancy¶
It is incredibly common for organizations to have different teams share clusters in an effort to save costs. It is critical to make sure that doing this does not result in noisy neighbor or security issues.
We see our customers using our multi-modal multitenancy capabilities extensively to support multiple AI/ML teams on the same Kubernetes cluster.
Issue 3: Secure Remote Access¶
Users with very different roles and responsibilities ( i.e. data scientists, operations, FinOps, security, contractor, 3rd party ISVs) need access and visibility into the health metrics for the underlying compute, storage infrastructure, GPUs and their applications.
How can organizations provide this to their users without compromising their security posture and still provide a great user experience?
Unified Management¶
Organizations requires a unified, central management platform for all Kubernetes clusters in use spanning both datacenter and cloud based environments. This central platform acts as a single pane of glass.
%%{init: {"flowchart": {"htmlLabels": false}} }%%
flowchart LR
subgraph cluster[Cluster - Data Center]
direction TB
op[Rafay Operator]-->prom[Prometheus]-->operator[Nvidia GPU Operator] --> gpu[Nvidia GPU]
style operator fill:#8fce00,stroke:#333,stroke-width:3px
style gpu fill:#8fce00,stroke:#333,stroke-width:3px
end
subgraph cluster2[Cluster - Cloud]
direction TB
op2[Rafay Operator]-->prom2[Prometheus]-->operator2[Nvidia GPU Operator] --> gpu2[Nvidia GPU]
style operator2 fill:#8fce00,stroke:#333,stroke-width:3px
style gpu2 fill:#8fce00,stroke:#333,stroke-width:3px
end
ops[Operations] -.->int[Internet]
ds[Data Scientists] -.-> int[Internet]
isv[ISVs] -.-> int[Internet]
con[Contractors] -.-> int[Internet]-.->rafay
subgraph rafay[Rafay SaaS]
direction TB
console[(Web Console)] --> tsdb[(Time Series DB)]
end
cluster-.->Internet-.-> rafay-.->Internet-.->cluster
cluster2-.->Internet-.->cluster2Integrated GPU and Kubernetes Metrics¶
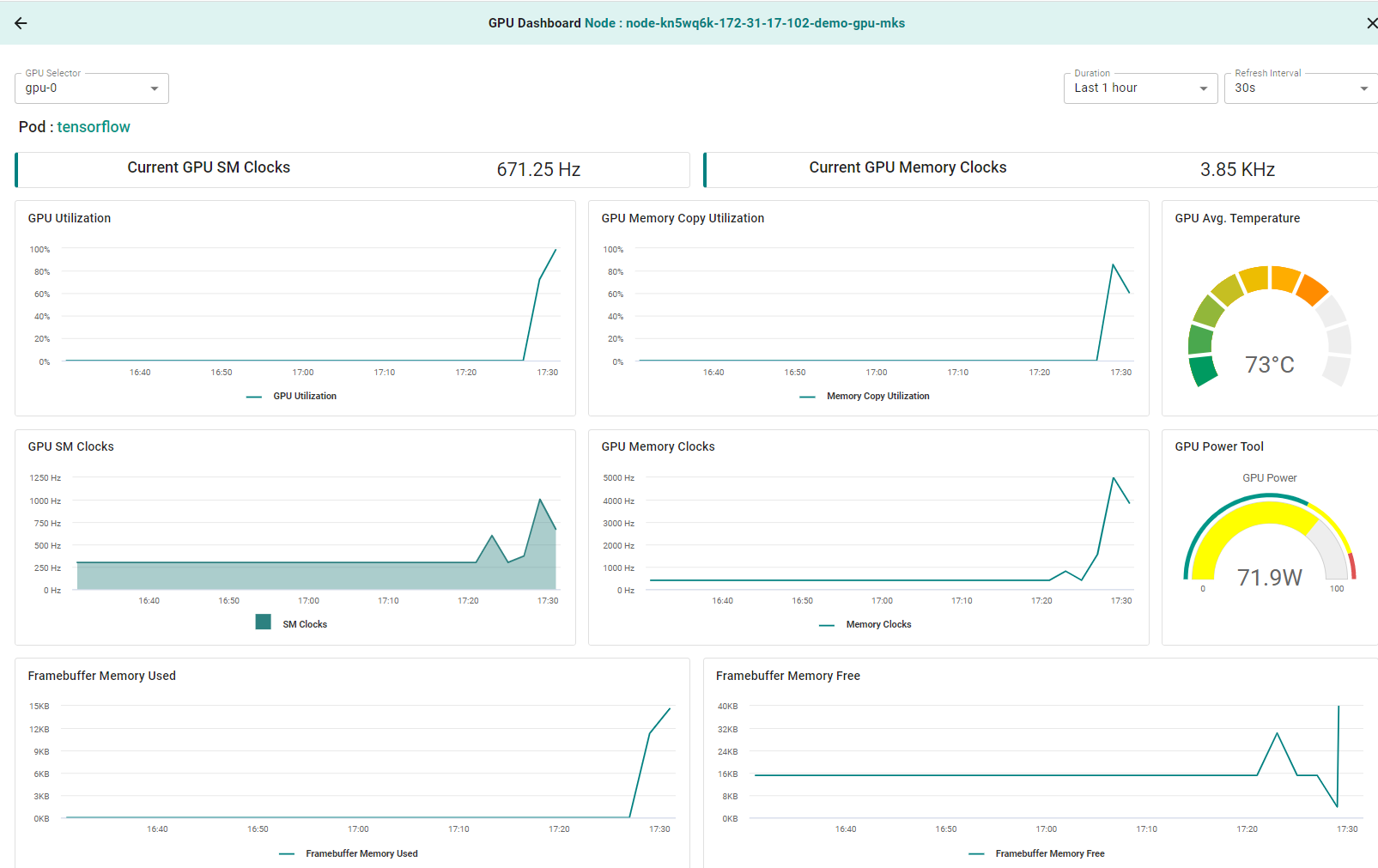
The platform automatically scrapes and aggregates both Kubernetes and GPU metrics at the controller in a multitenant time series database. These metrics are then made available (visualized) to users when they login.
In a nutshell, with Rafay, users that are employees, ISVs and external contractors are provided with detailed cluster and GPU metrics just by logging in.
- No need to provide privileged, remote access to infrastructure
- No need to provide access to internally hosted monitoring applications
Here is an example of the integrated GPU metrics dashboard that users are presented with.
Learn More¶
Anyone can sign up for a Free Rafay Org. Explore our detailed Getting Started guides for various use cases.
Register for one of our recurring webinars on multi-modal multitenancy to understand how you can deploy and operate cost effective infrastructure for multiple teams.
What Next?¶
In an upcoming blog, we will look at how organizations are looking to address their challenges for AI/ML environments that go beyond Kubernetes using Rafay's Environment Manager.