Vector Databases for Generative AI on Kubernetes¶
Many of our customers use Kubernetes extensively for AI/ML use cases. This is one of the reasons why we have turnkey support for Nvidia GPUs on EKS, AKS, Upstream Kubernetes in on-prem data centers. Recently, we have had several customers look at adding support for Generative AI to their applications. Doing so will require looking at a slightly different technology stack.
Traditional relational databases are adept at handling structured data. They do this by storing data in tables. However, AI use cases are focused on handling unstructured data (e.g. images, audio, and text). Data like this is not well suited for storage and retrieval in a tabular format. This critical technology gap with relational databases has opened the door for a new type of database called a Vector Database that can natively store and process vector embeddings. The rapid rise of large-scale generative AI models has further propelled the demand for vector databases.
In this blog, we will review why vector databases are well suited and critical for AI and Generative AI. We will then look at how you can deploy and operate vector databases on Kubernetes using the Rafay Kubernetes Operations Platform in just one step.
Where Vector Databases Shine¶
For search/retrieval, a set of vectors has to be retrieved that are most similar to a query (also in a form of a vector) that is embedded in the same Latent space. This retrieval procedure is called Approximate Nearest Neighbor (ANN) search. For example, a query could be find an image that are similar.
Handle Large Data Sets¶
For large-scale generative AI models to be effective, they need to be trained on large data sets. This allows them to capture intricate semantic and contextual information. Vector databases are well suited for handling and managing massive amounts of data.
Similarity Searches¶
Traditional keyword-based search methods fall short when it comes to complex semantics and context. Generated text from large-scale generative AI models enable similarity searches and matching to provide precise replies, recommendations, or matching results. Vector databases excel here providing high relevance and effectiveness for these use cases.
Multi Modal Data¶
Large-scale generative AI models are not limited to just text. For them to be effective, they need to also support multi modal data such as images and speech. Vector databases are adept at storing and processing "diverse data types".
Now, selecting the right vector database can have significant impact. At a high level, the critical criteria are
| Criteria | Description |
|---|---|
| Scalability | The vector database should scale well especially as the volume of data grows. |
| Cost | The cost of licensing and ongoing operations will be critical. |
| Latency | Semantic search and retrieval-augmented generation retrieval with the most relevant vectors with low latency. |
How to Deploy a Vector Database on Kubernetes¶
Choosing a vector database to store vector embeddings is a critical decision that can affect your architecture, compliance, and costs. There are two general categories of vector databases: Standalone Vector Database and Vector Search in Existing Databases. The standalone vector database category can be further divided into two categories: Hosted and Self Hosted. Popular self hosted, standalone vector databases are Weaviate, Milvus and Qdrant.
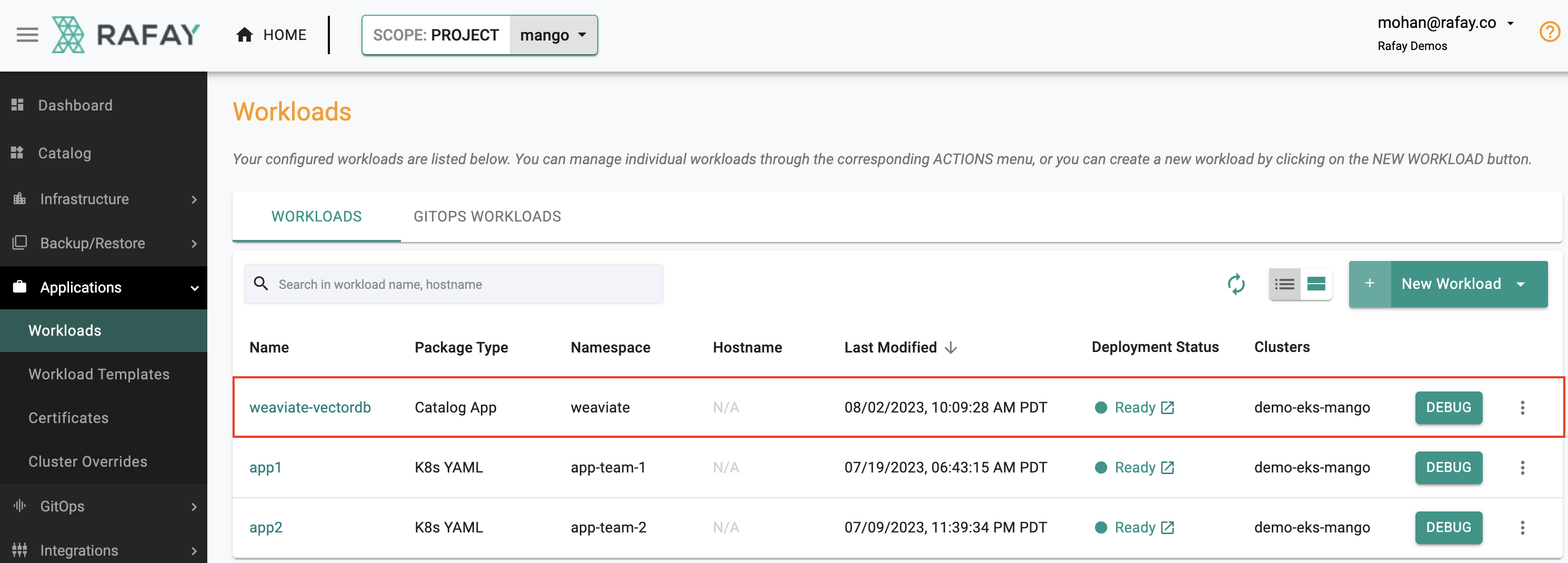
We have made the effort to make a number of popular vector databases available in Rafay's Catalog allowing users to deploy and use vector databases on Kubernetes in just a single step. Let's look at what it takes to deploy and operate a Weaviate vector database on an Amazon EKS cluster. Users just need to create a workload from the catalog, search for "weaviate" and deploy it to the cluster under management. See the video below for an example.
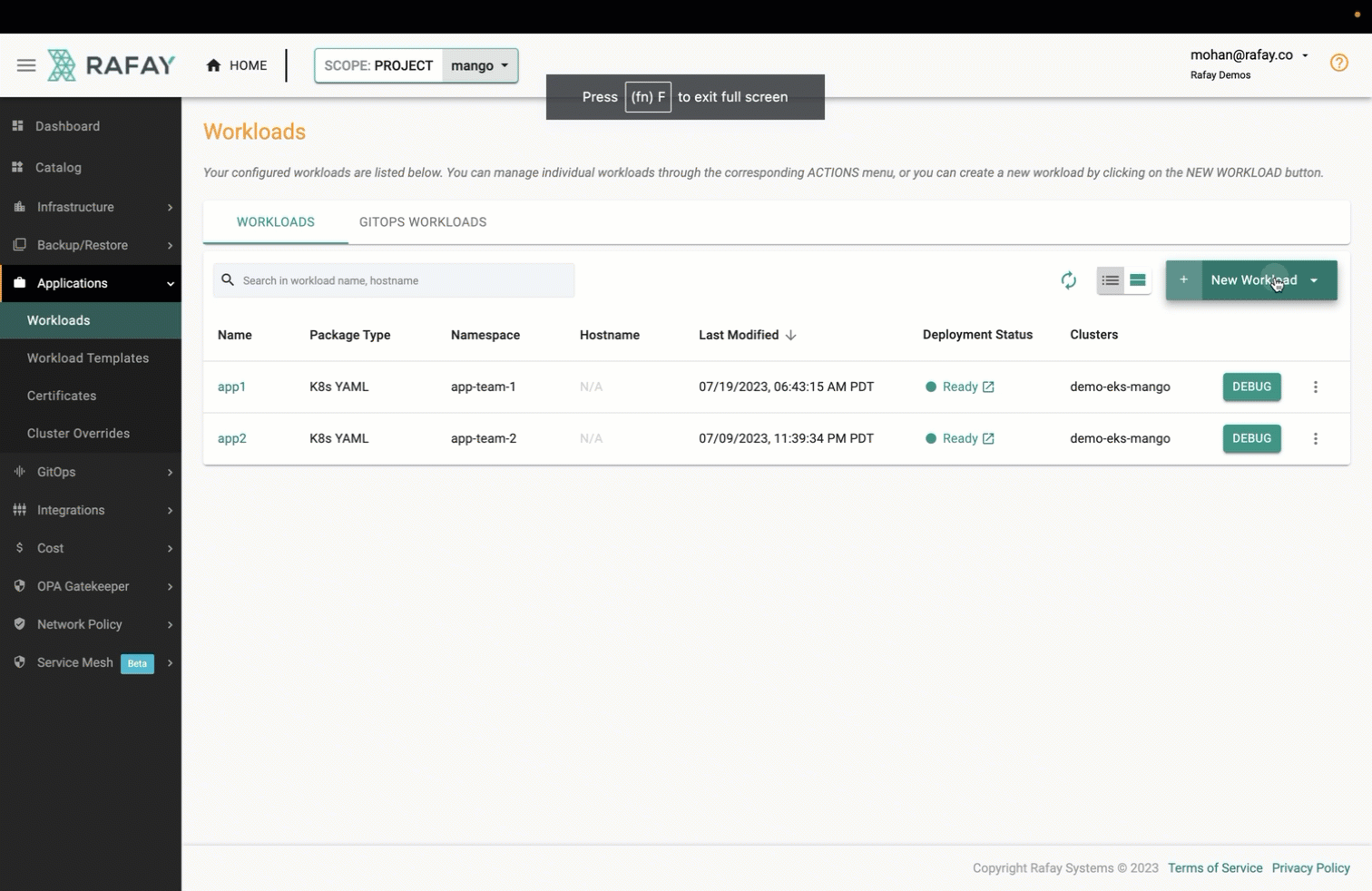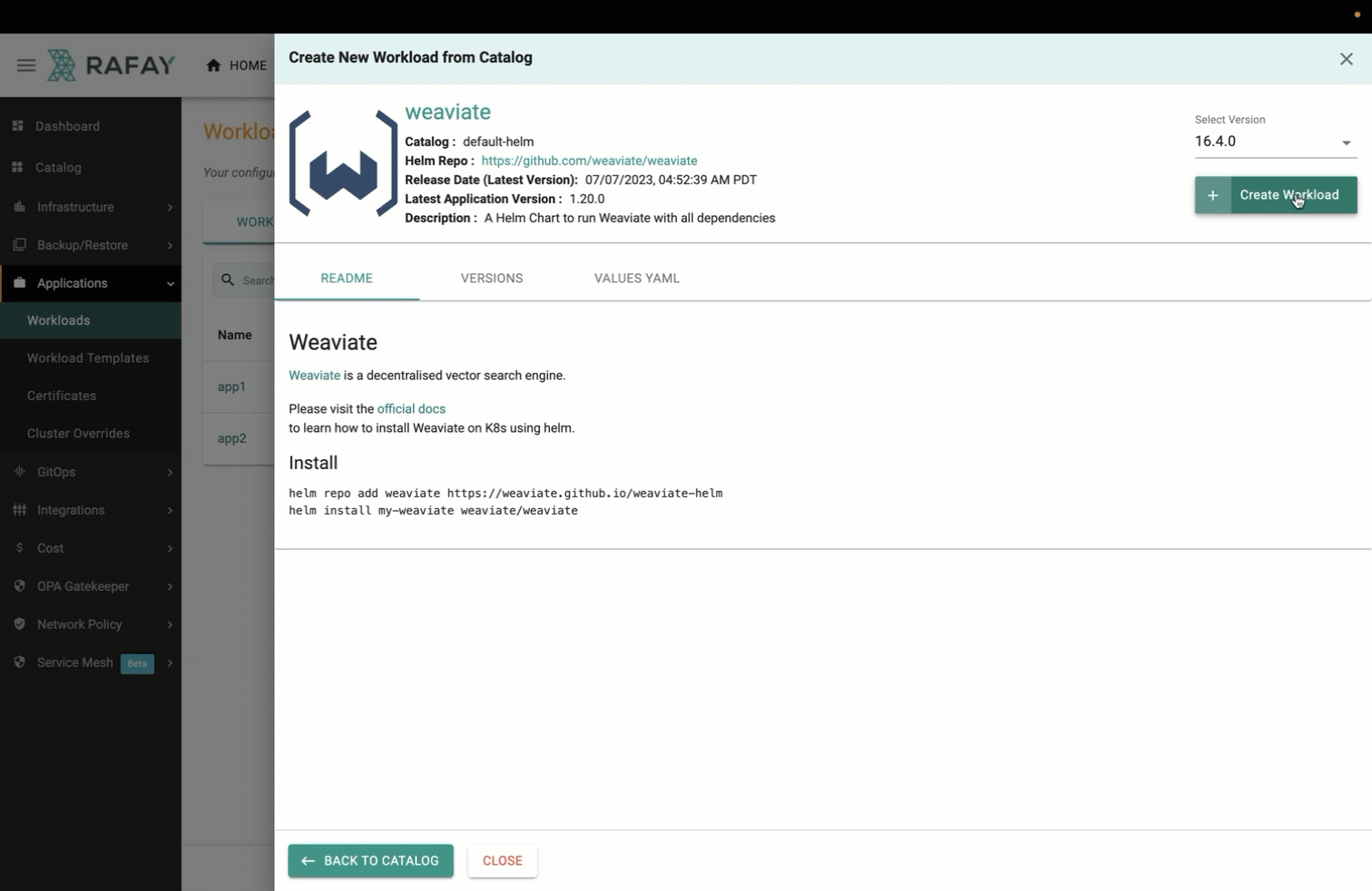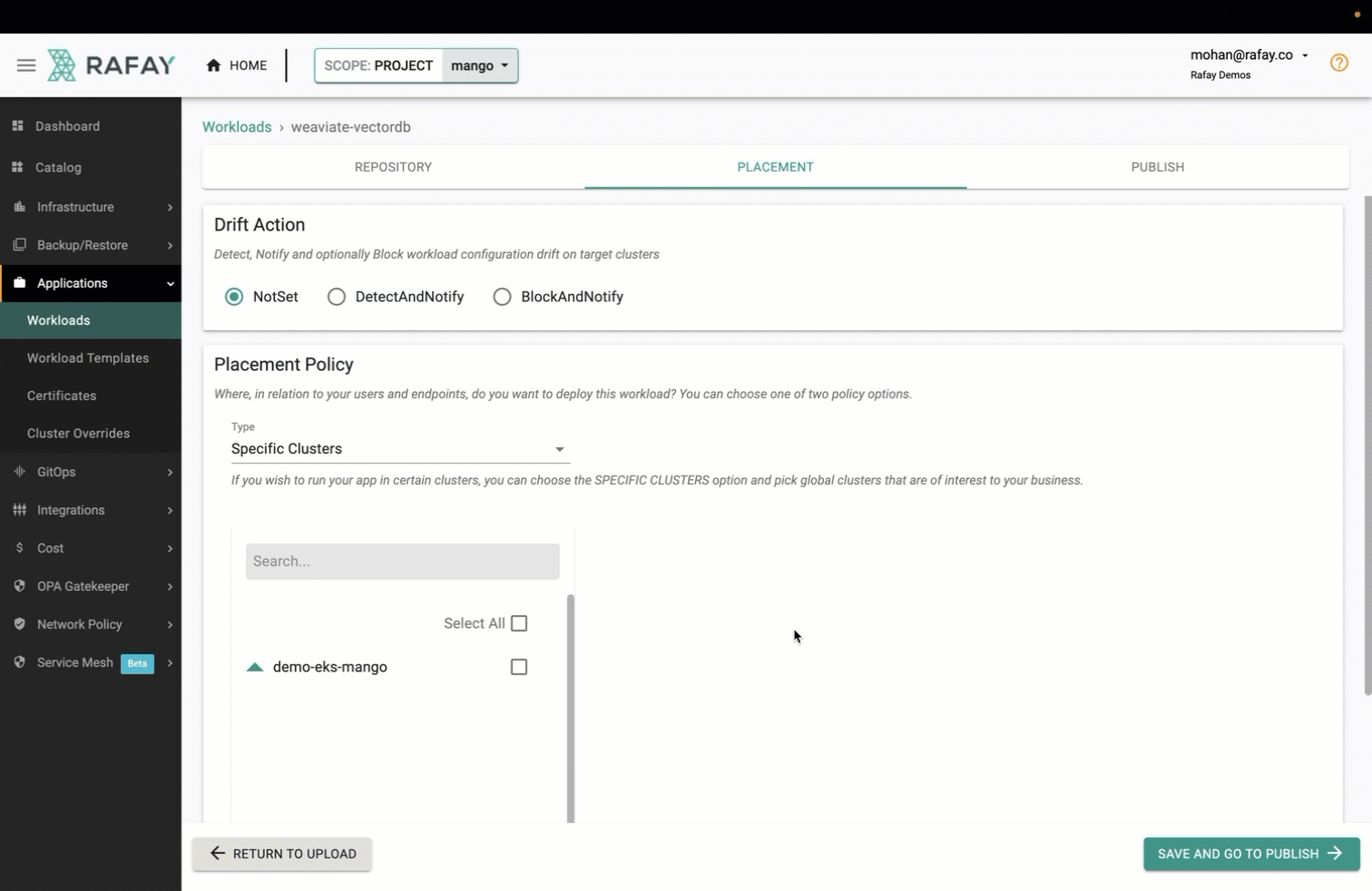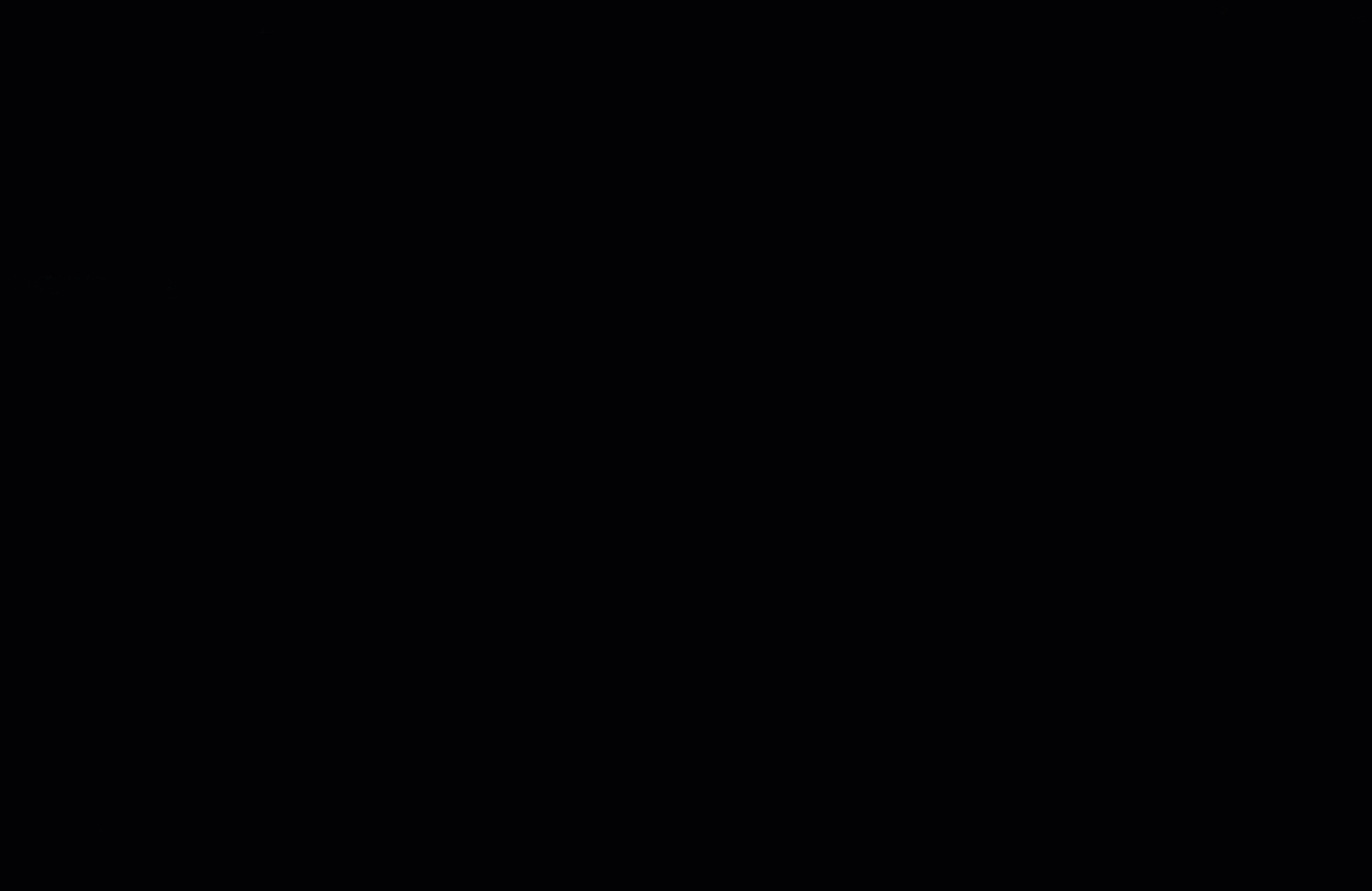
It can take a few minutes to create all the Kubernetes resources associated with the Weaviate workload. Once complete, your Weaviate vector database is ready for use. See screenshot below for an example of a successfully deployed Weaviate vector database on an Amazon EKS cluster using Rafay.
Important
Users can also do this declaratively and programmatically by embedding the RCTL CLI into their automation pipelines.
Next Steps¶
Try this out yourself by signing up for a free Rafay account.
Our sincere thanks to those who spend time reading our product blogs and provide us with feedback and ideas. Please Contact the Rafay Product Team if you would like us to write about specific topics.