Introduction to JupyterHub¶
This is part of a blog series on AI/Machine Learning. In the previous blog, we discussed Jupyter Notebooks, how they are different and the challenges organizations run into at scale with it. In this blog, we will look at organizations can use JupyterHub to take to provide access to Jupyter notebooks as a centralized service for their data scientists.

Why Not Standalone Jupyter Notebooks?¶
In the last blog, we summarized the issues that data scientists have to struggle with if they use standalone Jupyter notebooks. Let's review them again.
Installation & Configuration¶
Although data scientists can download, configure and use Jupyter notebooks on their laptops, this approach is not a very effective and scalable approach for organizations because
It requires every data scientist to become an expert on and perform the following:
- Spend time downloading and installing the correct versions of Python
- Create virtual environments, troubleshooting installs,
- Deal with system vs. non-system versions of Python,
- Install packages, dealing with folder organization
- Understand the difference between conda and pip,
- Learn various command-line commands
- Understand differences between Python on Windows vs macOS
Lack of Standardization¶
On top of this, there are other limitations that will impact the productivity of data scientists as well.
- Being limited by the compute capabilities of the laptop i.e. no GPU etc
- Data scientists pursuing Shadow IT for use of compute resources from public clouds
- Constantly download and upload large sets of data
- Unable to access data because of corporate security policies.
- Unable to collaborate (share notebooks etc) with other data scientists effectively
Important
JupyterHub's goal is to eliminate all these issues and help IT teams deliver Jupyter Notebooks as a managed service for their data scientists.
In a nutshell, with JupyterHub, IT/Ops can provide an experience for data scientists where they just need to login, explore data, write Python code. They do not have to worry about installing software on their local machine and can get access to a consistent, standardized and powerful environment to do their job.
JupyterHub Requirements for IT/Ops¶
JupyterHub is a Kubernetes native application and needs to be deployed and operated by IT/Ops in any environment (public/private cloud) where Kubernetes can be made available. Although, a Helm chart for JupyterHub is available, IT/Ops needs to do a whole lot more to operationalize it in their organization. Let's explore these requirements in greater detail.
| # | Requirement | Description |
|---|---|---|
| 1 | Prerequisites | As IT/Ops, how can I quickly deploy and operate the necessary pre-requisites for JupyterHub? i.e. Kubernetes cluster with all required add-ons for auto scaling, monitoring, gpu drivers, notifications, Ingress controller, cert-manager, external-dns etc. I may need to do this in different environments (i.e. public cloud: AWS, Azure, GCP, OCI or private cloud: data center) |
| 2 | Rapid Turnaround | Upon request by data scientists, IT/Ops need to provide an instance of JupyterHub optimized for their requirements with no delays. |
| 3 | Low Infra Costs | The costs associated with infrastructure to support the data scientists should be extremely low. The underlying infra should be configured to use low cost Spot instances and tools like Karpenter to ensure it is right sized. |
| 4 | Low Operational Costs | The personnel costs to deploy, operate and support this should be extremely low. This should not require a massive team to develop, maintain and support the infrastructure |
| 5 | Secure Access | All access to the JupyterHub instance should be secured via Single Sign On (SSO) with the organization’s Identity Provider (IdP) enforcing access policy. |
| 6 | Self Service Experience | IT/Ops should provide data scientists a self-service experience where they can select from a menu of available options, click to deploy in a few minutes and start using it. |
| 7 | Connection Security | All connections between various components needs to be secure, ideally using mTLS via a service mesh such as Istio. |
| 8 | Data Protection | All data created and used by data scientists needs to be automatically backed up. If/when required, IT/Ops should be able to perform data recovery in minutes. |
| 9 | Data Access | The data scientist should have automatic access to data that they can use in their notebooks |
| 10 | Data Analytics | The data scientist should have the ability to seamlessly perform data analytics using Spark etc directly from their Jupyter notebooks |
| 11 | Environment Promotion | The data scientist should have the ability to seamlessly promote the new code from Dev -> QA and eventually to Prod with appropriate workflows/approvals etc |
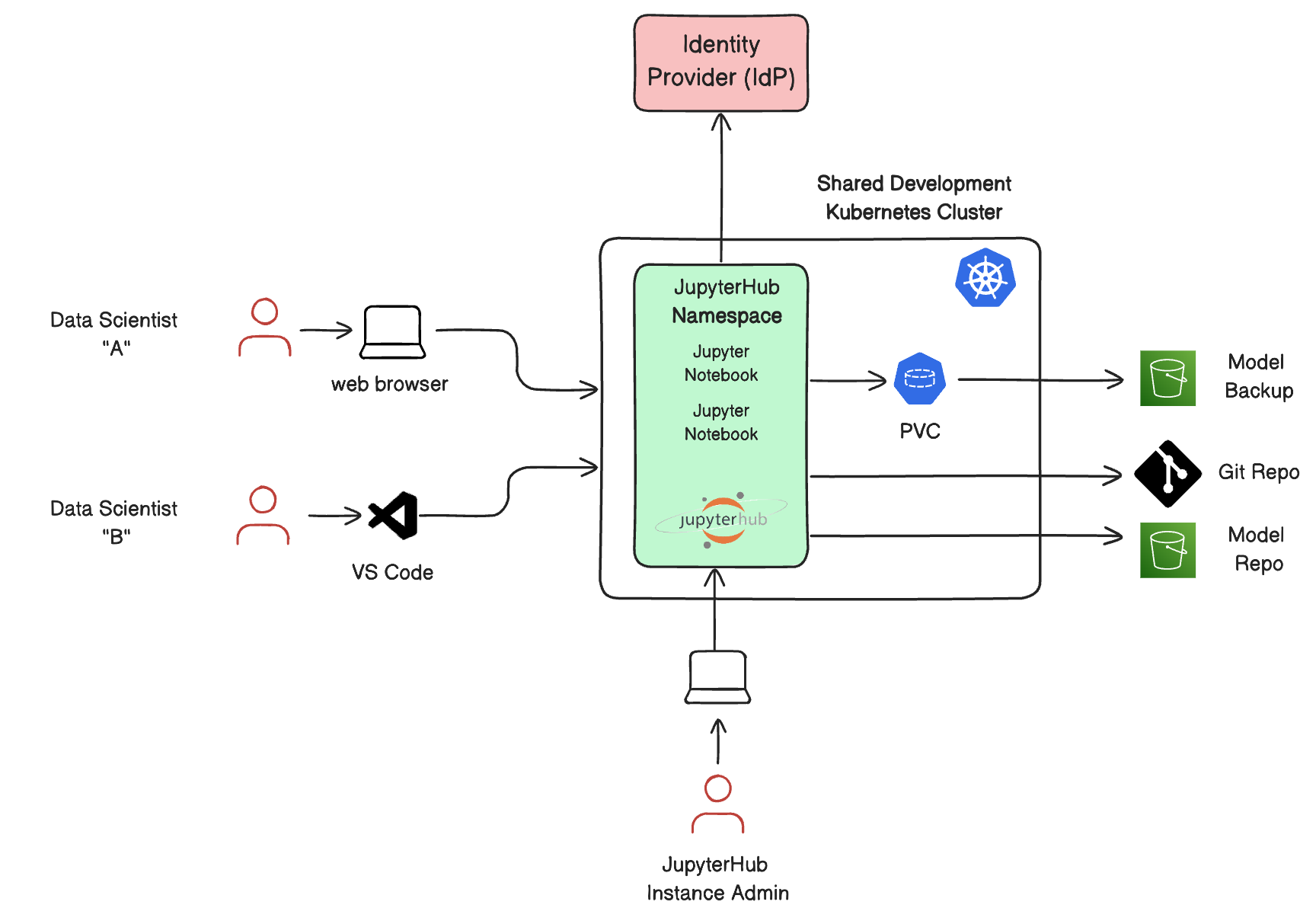
The diagram below shows what a typical JupyterHub environment managed by IT/Ops would look like at steady state.
Rafay's Templates for AI/GenAI¶
The Rafay team has been assisting many of our customers operationalize JupyterHub for their data scientists. We have packaged the best practices, security and streamlined the entire deployment process so that IT/Ops can save significant amount of time and money. The entire process is now a 1-click deployment experience for IT/Ops and they are now starting to offer this to their data scientist teams as a self service experience. Learn more about Rafay's template for JupyterHub
Important
This is available for all Rafay customers that have licensed the AI/GenAI suite.
Blog Ideas¶
Sincere thanks to readers of our blog who spend time reading our product blogs. This blog was authored because we are working with several customers that are expanding their use of Jupyter notebooks on Kubernetes and AWS Sagemaker using the Rafay Platform. Please contact us if you would like us to write about other topics.