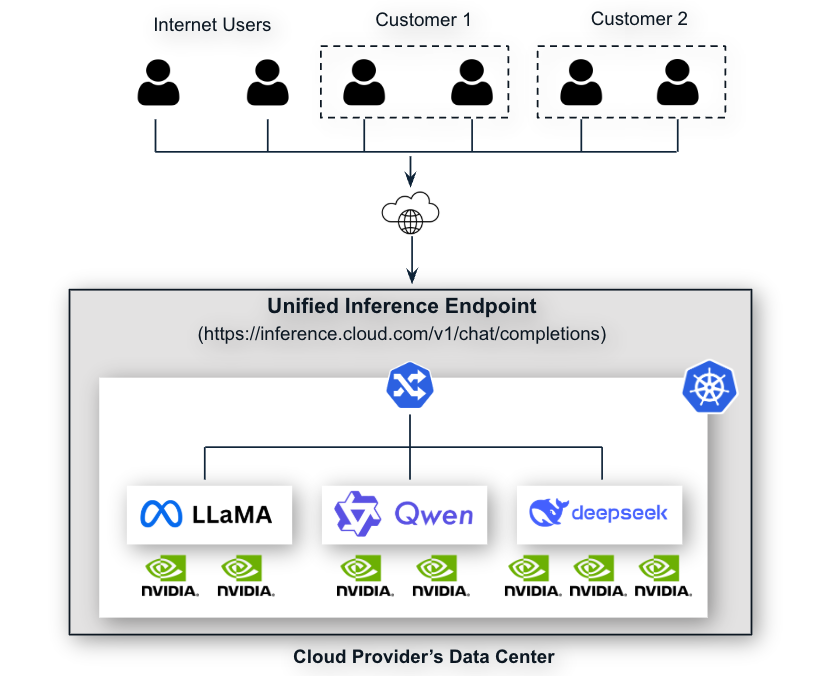
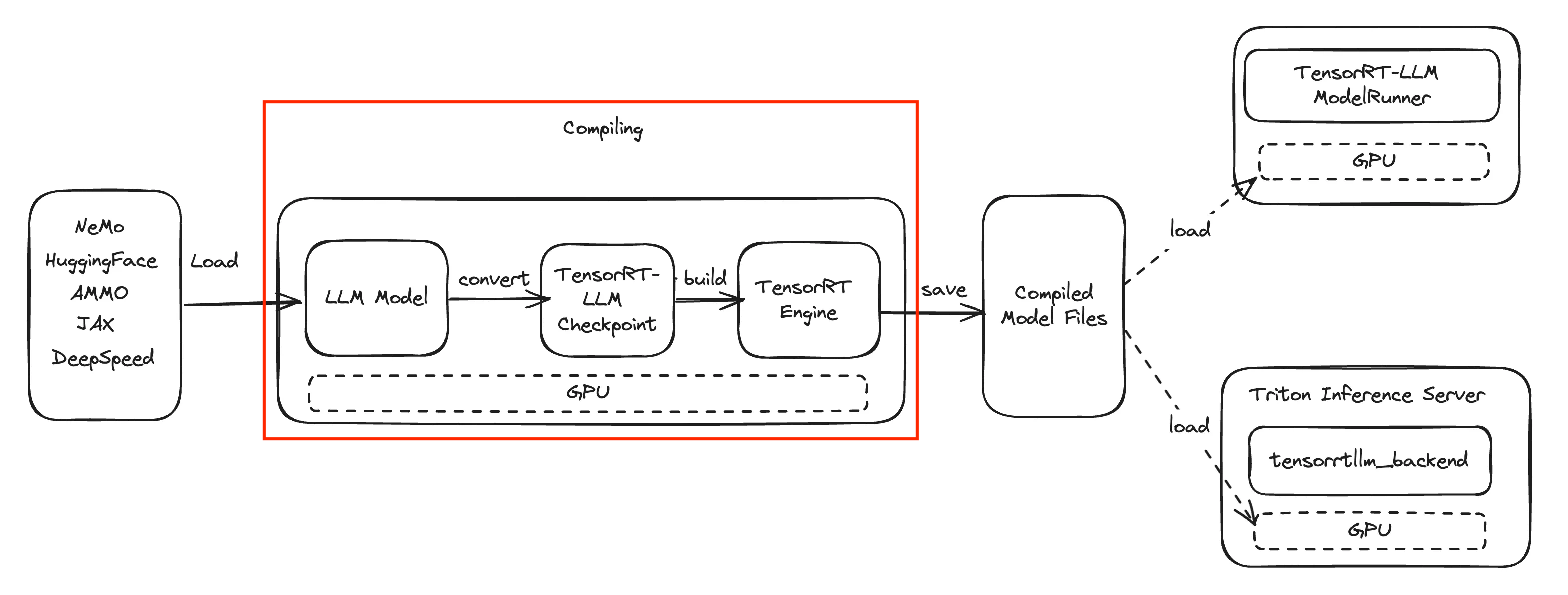
Introduction to User Namespaces in Kubernetes
In Kubernetes, some features arrive quietly, but leave a massive impact. Kubernetes v1.33 is turning out to be one such release where there are some features with massive impact. In the previous blog, my colleague described how you can provision and operate Kubernetes v1.33 clusters on bare metal and VM based environments using Rafay.
In this blog, we will discuss a new feature in v1.33 called User Namespaces. This feature is not a headline grabber such as a service mesh etc, but is a game changer for container security.