If you've spent years submitting batch jobs with Slurm, moving to a Kubernetes-based cluster can feel like learning a new language. The concepts are familiar — resource requests, job queues, priorities — but the vocabulary and tooling are different. This guide bridges that gap, helping HPC veterans understand how Kubernetes handles workloads and what that means day-to-day.
Infra operators managing GPU-enabled Kubernetes clusters often need a fast and secure way to validate GPU visibility, driver health, and runtime readiness without exposing the cluster directly or relying on bastion hosts, VPNs, or manually managed kubeconfigs.
With Rafay's zero trust kubectl, operators can securely access remote Kubernetes resources and execute commands inside running pods from the Rafay platform. A simple but powerful example is running nvidia-smi inside a GPU Operator pod to confirm that the NVIDIA driver stack, CUDA runtime, and GPU devices are functioning correctly on a remote cluster.
In this post, we walk through how infra operators can use Rafay's zero trust access workflow to run nvidia-smi on a remote GPU-based Kubernetes cluster.
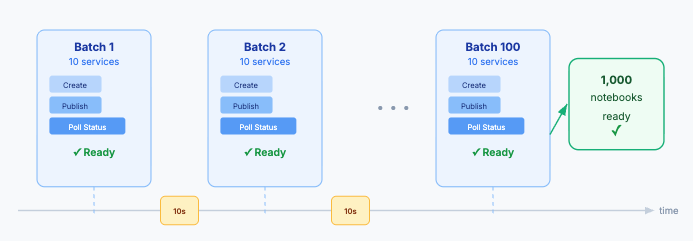
Running a hackathon is hard. Running a GPU-powered hackathon for thousands of participants — where every developer needs a fully configured environment (notebooks, developer pod etc) with dedicated GPU resources, ready to go the moment the event kicks off — is an entirely different class of problem. This is exactly where Rafay's platform has helped change the game for GPU Cloud providers.
The Model Context Protocol (MCP) is an open standard that enables AI assistants to securely interact with external tools and systems. When used with Kubernetes, MCP allows an AI assistant to execute operations (for example, kubectl commands), retrieve live cluster state, and reason about results without requiring users to manually copy and paste output into a chat interface.
This blog uses Claude Desktop as an example AI assistant. The same approach applies to any MCP-compatible AI client.
For platform administrators, this capability enables controlled, auditable, and policy-driven AI-assisted cluster operations.
For production environments, the recommended approach is to run the MCP server locally and connect to your Kubernetes cluster using a Rafay Zero Trust Kubectl Access (ZTKA) kubeconfig.
In this model:
The MCP server runs on the administrator’s workstation
Cluster access is established through Rafay’s ZTKA secure relay
No inbound access to the cluster is required
No VPN tunnels or exposed Kubernetes API endpoints are needed
This architecture aligns with zero-trust security principles and enterprise compliance requirements.
As part of our continuous effort to bring the latest Kubernetes versions to our users, support for Kubernetes v1.35 will be added soon to the Rafay Operations Platform for MKS cluster types.
Both new cluster provisioning and in-place upgrades of existing clusters are supported. As with most Kubernetes releases, this version deprecates and removes a number of features. To ensure zero impact to our customers, we have validated every feature in the Rafay Kubernetes Operations Platform on this Kubernetes version. Support will be promoted from Preview to Production in a few days and made available to all customers.
Important: Platform Version 1.2.0 Required
Kubernetes v1.35 requires etcd version 3.5.24 which is delivered as part of Rafay Platform Version 1.2.0. When creating new clusters based on Kubernetes v1.35, select Platform Version 1.2.0 along with it. For upgrading existing clusters to Kubernetes v1.35, upgrade to Platform Version 1.2.0 first or together with the Kubernetes upgrade. Clusters cannot be provisioned or upgraded to Kubernetes v1.35 without Platform Version 1.2.0.
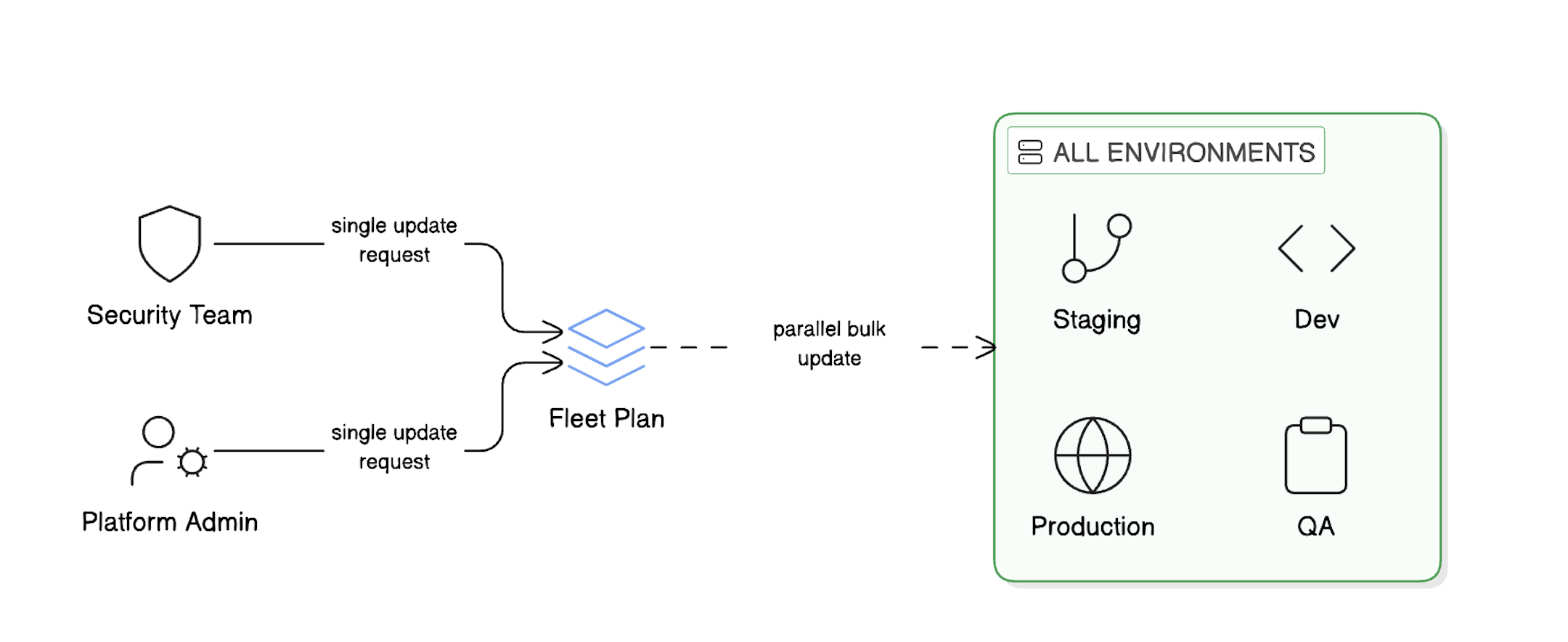
As organizations scale their cloud infrastructure, managing dozens or even hundreds of environments becomes increasingly complex. Whether you are rolling out security patches, updating configuration variables, or deploying new template versions, performing these operations manually on each environment is time-consuming, error-prone, and simply unsustainable.
Fleet Plans solve this challenge—a powerful feature that eliminates the need to manage environments individually by enabling bulk operations across multiple environments in parallel.
Fleet Plans provide a streamlined workflow for managing multiple environments at scale, enabling bulk operations with precision and control.
Note: Fleet Plans currently support day 2 operations only, focusing on managing and updating existing environments rather than initial provisioning.
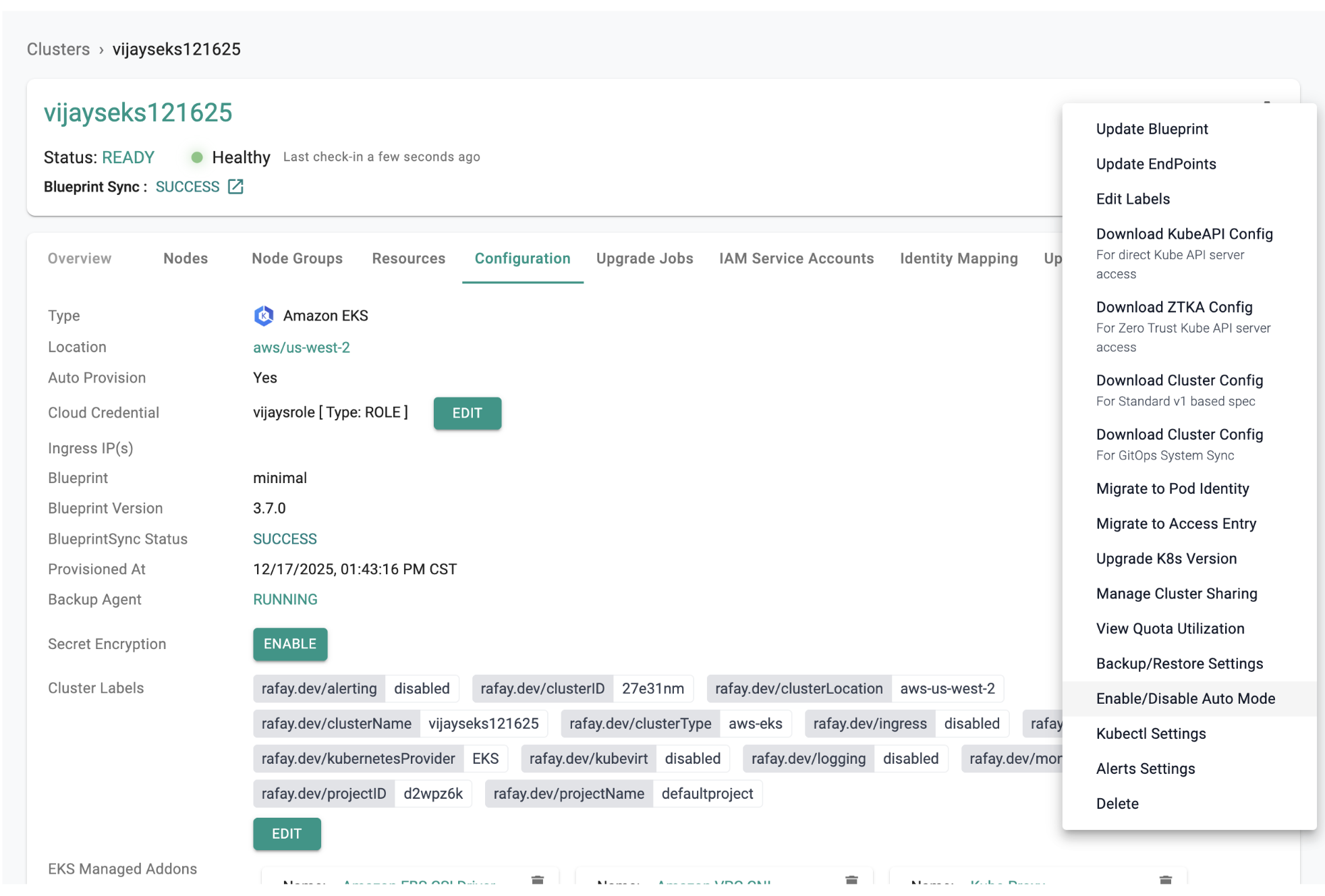
Amazon EKS Auto Mode simplifies cluster management by automatically handling worker node scaling, patching, and other operational tasks. This guide walks you through migrating your existing EKS clusters to Auto Mode using Rafay.
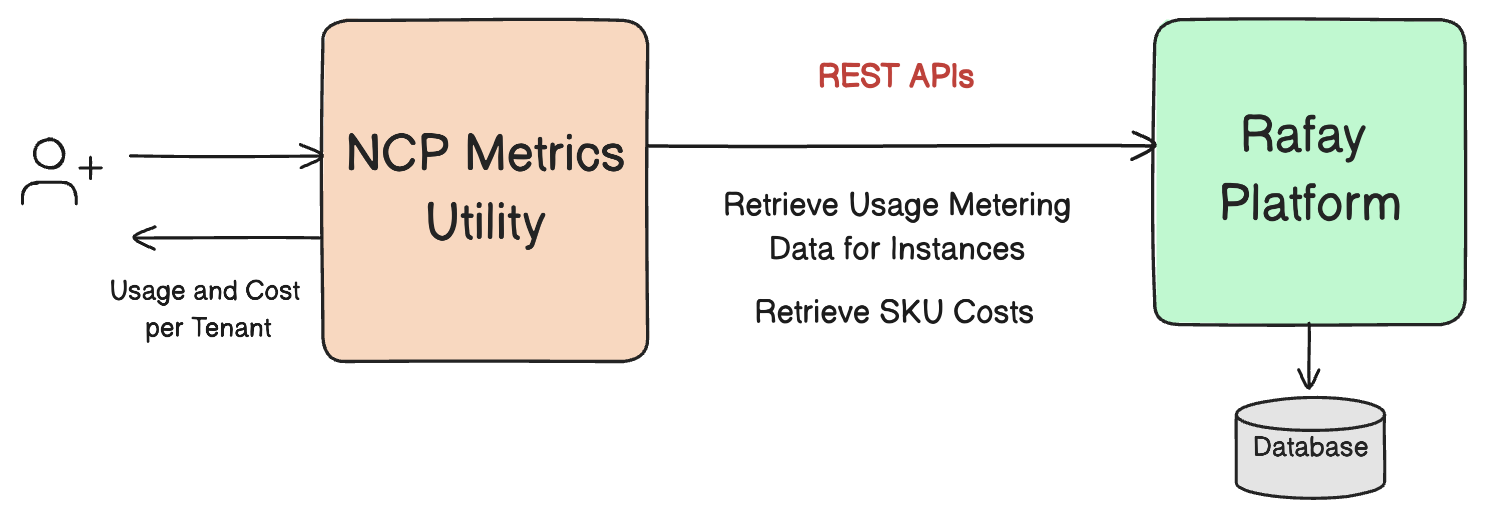
Cloud providers building GPU or Neo Cloud services face a universal challenge: how to turn resource consumption into revenue with accuracy, automation, and operational efficiency. In our previous blog, we demonstrated how to programmatically retrieve usage data from Rafay’s Usage Metering APIs and generate structured CSVs for downstream processing in an external billing platform.
In this follow-up blog, we take the next step toward a complete billing workflow—automatically transforming usage into billable cost using SKU-specific pricing. With GPU clouds scaling faster than ever and enterprise AI workloads becoming increasingly dynamic, providers must ensure their billing engine is consistent, transparent, and tightly integrated with their platform. The enhancements described in this blog are designed exactly for that.
The Kubernetes community has officially started the countdown to retire Ingress NGINX, one of the most widely used ingress controllers in the ecosystem.
SIG Network and the Security Response Committee have announced that Ingress NGINX will move to best-effort maintenance until March 2026, after which there will be no new releases, no bug fixes, and no security updates. 
At the same time, the broader networking story in Kubernetes is evolving: Gateway API is now positioned as the successor to Ingress. In this blog, we describe why this is happening, when a replacement make sense, and how/when you should migrate.
As the demand for AI training and inference surges, GPU Clouds are increasingly looking to offer their users higher-level, turnkey AI services, not just raw GPU instances. Some customers may be familiar with NVIDIA Run:ai as an AI workload and GPU orchestration platform.
Delivering NVIDIA Run:ai as a scalable, repeatable managed service—something customers can select and provision with a few clicks—requires deep automation, lifecycle management, and tenant isolation capabilities. This is exactly what Rafay provides.
With Rafay, GPU Clouds, including NVIDIA Cloud Partners, can deliver NVIDIA Run:ai as a managed service with self-service provisioning, ensuring customers receive a fully configured NVIDIA Run:ai environment automatically, complete with GPU infrastructure, a Kubernetes cluster, necessary operators, and a ready-to-use NVIDIA Run:ai tenant. This post explains how Rafay enables cloud providers to industrialize NVIDIA Run:ai provisioning into a consistent, production-ready managed service.