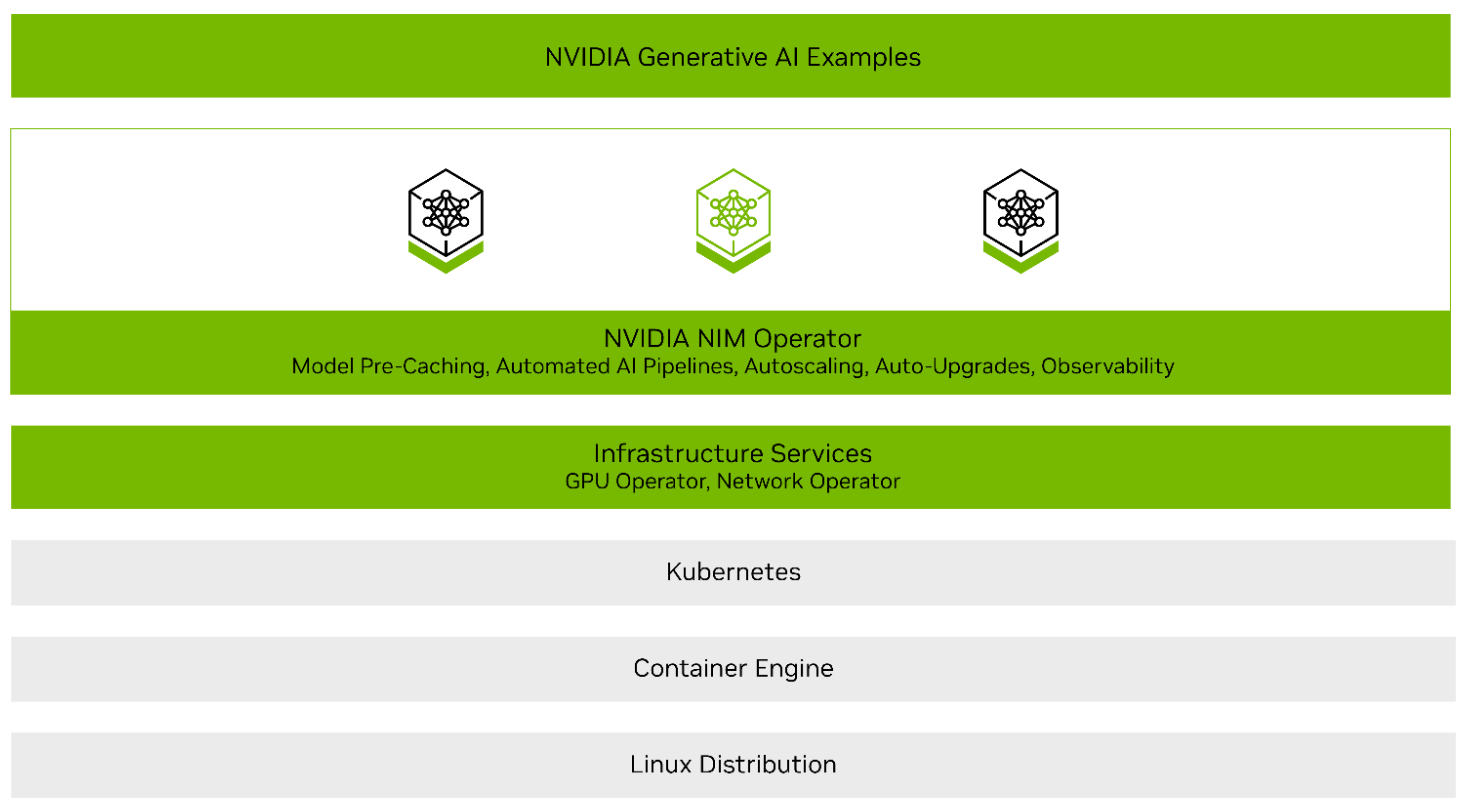
Granular Control of Your EKS Auto Mode Managed Nodes with Custom Node Classes and Node Pools
With a couple of releases back, we added EKS Auto Mode support in our platform for doing either quick configuration or custom configuration. In this blog, we will explore how you can create an EKS cluster using quick configuration and then dive deep into creating custom node classes and node pools using addons to deploy them on EKS Auto Mode enabled clusters.